[리뷰] LLaMA: Open and Efficient Foundation Language Models
Introduction
최근 몇 년간, 언어 모델의 크기는 Scaling laws에 따라 지속적으로 증가하는 추세였다. 이는 모델의 성능 향상에는 기여했지만, 모델을 서빙할 때의 추론 예산을 무시하는 문제점이 있었다. 따라서 기업들은 목표 성능을 달성한 후에는 학습 속도가 아닌 추론 속도가 가장 빠른 모델을 선호하는 경향이 있다.
2022년 5월 Meta에서 OPT-175B를 발표하였다. 하지만 OPT는 GPT-3와 동일한 모델 크기를 갖고 있음에도 불구하고 성능에서 큰 차이가 있었다. 논문에서도 모델의 성능을 자랑하는 것보다는 왜 이 모델이 성능이 부족했는지에 대한 탐구에 중점을 두고 있다.
이후 Meta는 절치부심해서 새로운 모델을 개발하였으며, Google Deepmind에서 발표한 Chinchilla Scaling Laws 연구 결과에 영감을 받아 GPT-3(175B)보다 더 작으면서 고성능인 LLaMA을 선보였다.
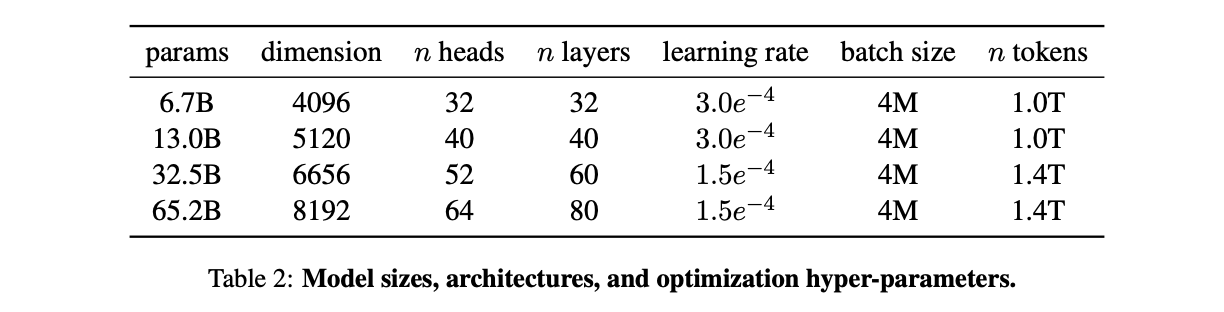
GPT-3가 1.3B부터 175B까지 네 가지 모델을 제공한 것과 마찬가지로, LLaMA도 7B, 13B, 33B, 65B의 네 가지 모델을 제공한다.
Approach
Pre-training Data
LLaMA는 공개적으로 사용 가능하고 오픈 소스와 호환되는 데이터만 사용한다는 제한을 두고 다른 LLM을 학습하는 데 활용된 데이터 셋을 재사용하였다. 사용된 데이터셋과 데이터의 비율은 아래와 같다.
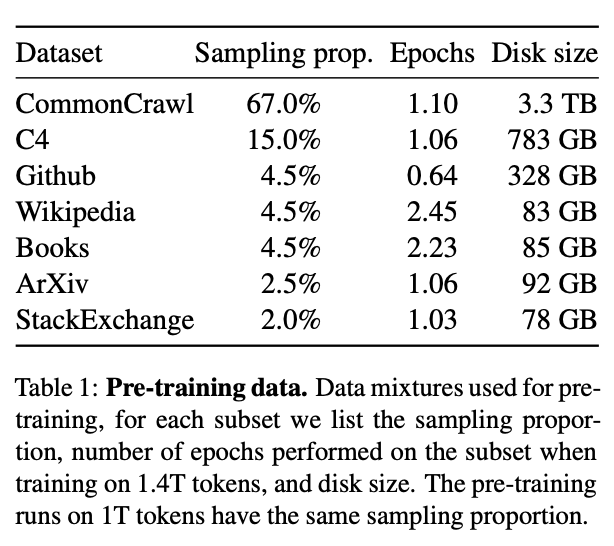
데이터셋 구성을 보면 CommonCrawl, C4의 합계가 82%로, 이는 GPT-3에 투입된 비율과 같다.
웹 크롤링 데이터는 품질이 낮기 때문에 정제를 잘하는 것이 중요하다. 이를 위해 Meta에서는 별도의 모델을 만들어 수집한 페이지가 Wikipedia의 인용 출처로 쓰일 수 있는지 여부를 판별하는 분류기를 학습시키고, 이를 통과한 페이지만 학습에 투입하였다.
다음으로 Google BigQuery에서 사용되는 공개 GitHub 데이터셋을 사용하였다. 코드 데이터의 논리성이 언어 학습에 도움을 준다고 한다.
이외에 2022년 6월부터 8월까지 20개국의 Wikipedia 데이터가 높은 비중으로 학습에 투입되었고, 논리적인 태스크 수행을 위해 도서와 논문 데이터도 포함된 것으로 보인다.
토크나이저는 OPT에서 사용했던 GPT 스타일의 BBPE에서 BPE로 변경하였고, Unknown 토큰을 대비하여 폴백 옵션을 추가하였다.
Architecture
LLaMA의 아키텍처는 Vanilla Transformer 아키텍처에서 빠른 학습을 위해 일부 구조를 개선하였다.
- Pre-normalization [from GPT-3]
- SwiGLU activation function [from PaLM]
- Rotary Embeddings [from GPTNeo]
- absolute positional embeddings를 제거하는 대신 RoPE (rotary positional embeddings) 방식을 사용하여 학습 시 2048 토큰보다 긴 입력도 처리할 수 있다.
Optimizer
LLaMA는 다음과 같은 하이퍼파라미터를 사용하여 AdamW Optimizer를 통해 학습된다.
- \(\beta_1\) = 0.9, \(\beta_2\) = 0.95
- weight decay = 0.1
- gradient clipping = 1.0
- warmup steps = 2000
- 최종 학습률이 최대 학습률의 10%가 되도록 cosine learning rate scheduler 사용
Efficient implementation
모델의 학습 속도 향상을 위해 몇 가지 최적화를 수행하였다.
- 메모리 사용량과 런타임을 줄이기 위해 multi-head attention을 효율적으로 구현한
xformers라이브러리를 사용하였다. - backward pass시 linear layer의 출력과 같이 계산 비용이 많이 드는 activation을 그대로 저장함으로써 재계산되는 activation을 줄였다.
- activation의 계산과 네트워크를 통한 GPU 간의 통신을 최대한 중첩시켜 수행하였다.
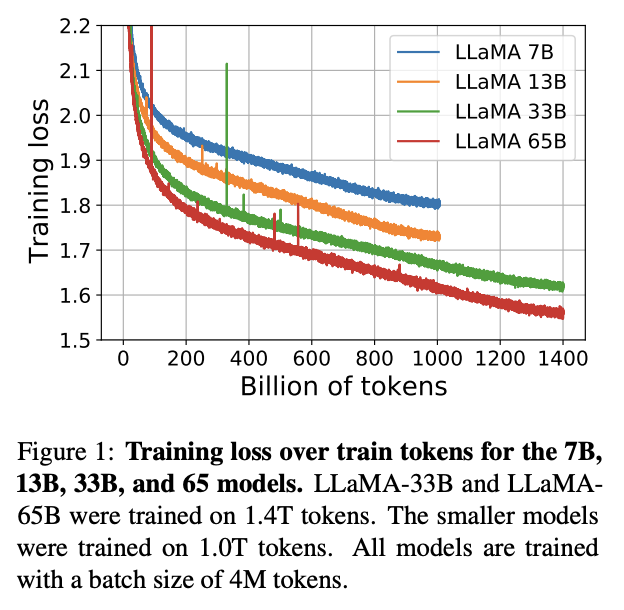
이로써 학습 시간은 LLaMA-65B 학습을 80G A100 2048장, 256노드로 진행해서 1.4T 토큰 학습에 21일 걸렸다고 한다.
Main results
저자들은 Zero-shot 및 Few-shot task를 포함한 다양한 벤치마크에서 GPT-3, Gopher, Chinchilla, PaLM과 같은 Foundation Model과 LLaMA를 비교하였다. 이중 대표적인 벤치마크에 대한 결과는 다음과 같다.
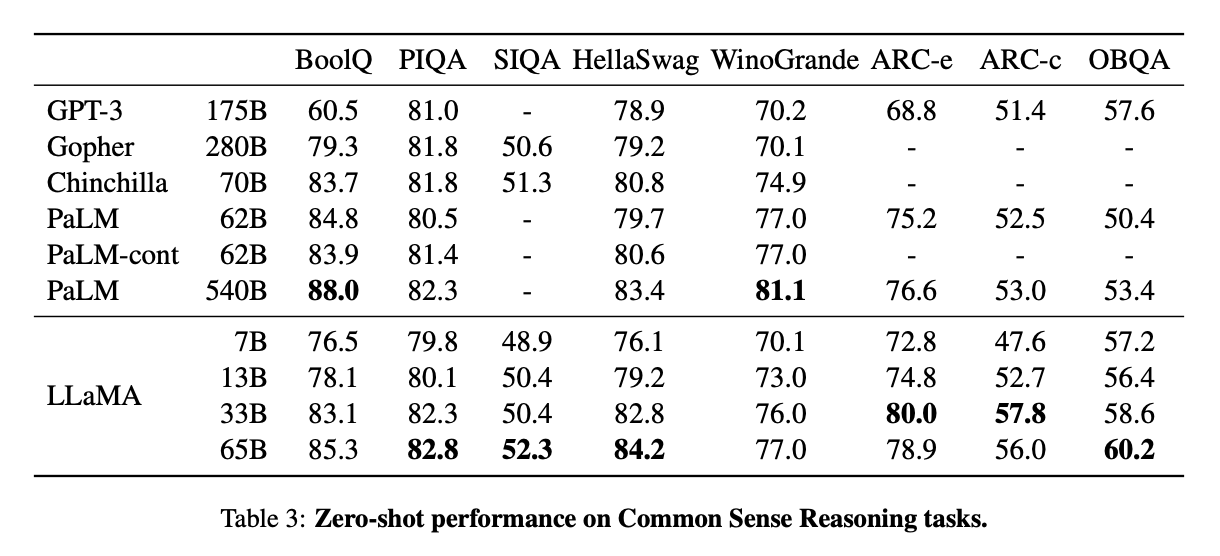
- LLaMA-65B는 BoolQ를 제외한 모든 벤치마크에서 Chinchilla-70B보다 성능이 뛰어나다.
- LLaMA-65B는 BoolQ와 WinoGrande를 제외한 모든 벤치마크에서 PaLM540B보다 성능이 뛰어나다.
- LLaMA-13B 또한 GPT-3에 비해 10배 더 작은 크기임에도 불구하고 PIQA, OBQA를 제외한 대부분의 벤치마크에서 우수한 성능을 보인다.
해당 결과를 통해, 같은 모델 크기에서 LLaMA가 경쟁 모델 대비 우수한 성능을 보이며, 작은 모델에서도 일정 수준 이상의 성능을 발휘할 수 있음을 확인할 수 있다.
Massive Multitask Language Understanding5
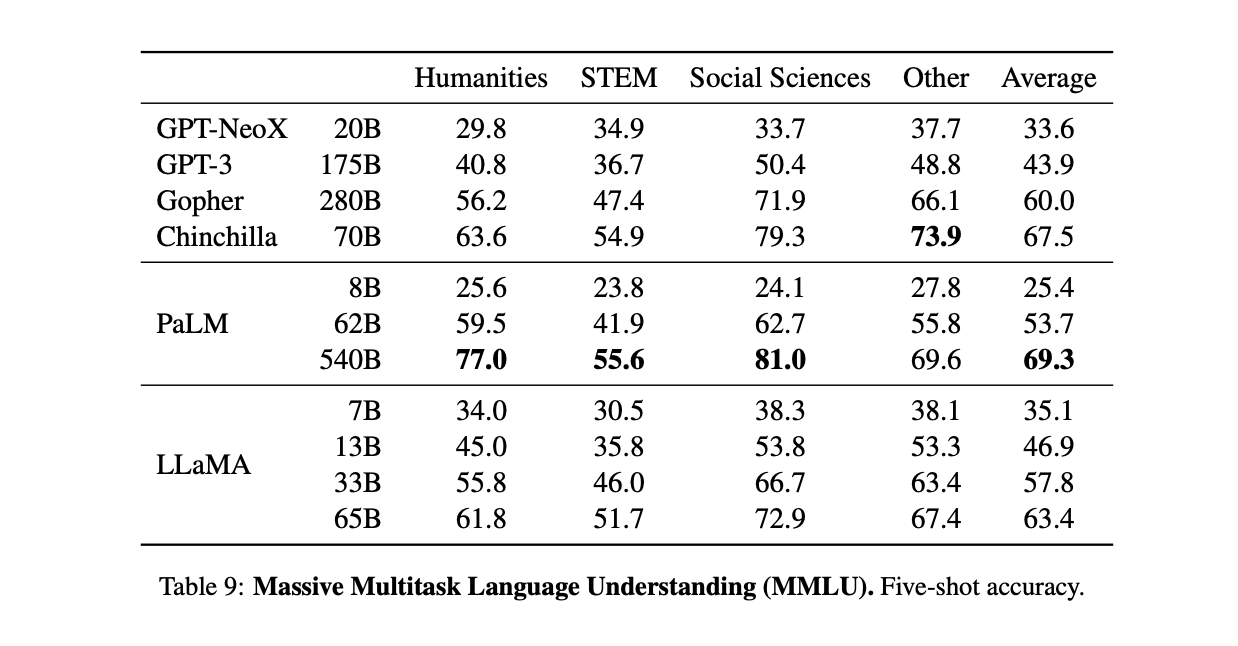
- MMLU는 모델의 멀티태스크 정확도를 측정하는 데이터셋으로 인문학, 초등 수학, 역사, 컴퓨터 과학, 법률 등 57개의 주제를 포함하고 있다. MMLU를 잘 수행하기 위해서는 모델이 광범위한 상식을 갖추고 다양한 문제를 해결할 수 있는 능력이 필요하다.
- LLaMA-65B는 GPT-3보다 더 우수하지만 Chinchilla와 PaLM에 비해 떨어지는 벤치마크 결과를 보인다.
- 저자들은 책과 논문 데이터가 Gopher와 Chinchilla에 비해 적은 양으로 학습되었기 때문이라고 분석하고 있다. (LLaMA : 177GB, Gopher, Chinchilla : 2TB)
Instruction Tuning
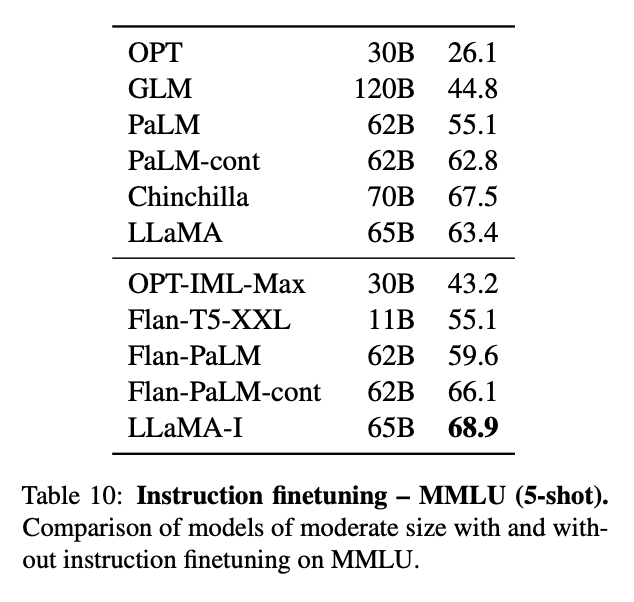
다음은 LLaMA-65B에 instruction tuning을 적용하고 MMLU에서 5-shot 평균을 낸 결과이다.
아주 적은 양의 명령어 데이터 파인 튜닝만으로 MMLU의 성능이 향상되고 instruction 수행 능력이 더욱 향상되는 것을 관찰할 수 있었다. (63.4 → 68.9)
하지만 77.4%라는 SOTA 성능을 끌어낸 OpenAI의 code-davinci-002 모델에는 미치지 못하는 모습을 볼 수 있다.
Couclusion
LLaMA-13B는 GPT-3의 10분의 1 크기에도 불구하고, 대부분의 벤치마크에서 GPT-3보다 높은 성능을 보였다. 한 발 더 나아가, LLaMA-65B는 Chinchilla, Gopher, GPT-3, PaLM 등의 경쟁 모델들과 비슷하거나 더 나은 결과를 보였다.
OPT의 성능 저하 원인 중 하나는 180B 토큰으로 학습되어 학습량이 부족하다는 점이었다. (GPT-3의 경우 300B 토큰으로 학습) 이에 비해 1.4T 토큰으로 학습한 LLaMA는 더 많은 학습 데이터를 기반으로 뛰어난 성능을 보이는 것은 이전에 Chinchilla에서 확인된 바와 같이 예상 가능한 결과이다.
더불어, Chinchilla보다 LLaMA의 성능이 대체로 높은 것으로 나타났는데, 이는 정제된 웹 크롤링 데이터를 활용한 것이 효과를 발휘한 것으로 해석할 수 있다.
이후 LLaMA 연구진들은 향후 더 큰 모델에 더 많은 token을 학습시킨 모델을 발표할 계획이라고 밝혔다.
그리고 2023년 7월, Meta AI팀은 학술적 및 상업적 이용이 전부 가능한 오픈소스 LLM으로 LLaMA-2를 발표하였다. 이 모델은 LLaMA-1보다 40% 더 많은 데이터(2T)를 활용하고, context length도 2배로 늘어난(2048에서 4096으로) 특징을 가지고 있다.