[리뷰] LoRA: Low-Rank Adaptation of Large Language Models
Introduce
PEFT(Parameter Efficient Fine-Tuning)는 모델의 모든 파라미터를 튜닝하는 것이 아닌 일부 파라미터만을 튜닝함으로써 모델의 성능을 적은 자원으로도 높게 유지하는 방법론이다.
GPT-3와 같은 매우 큰 언어 모델이 등장하면서 다양한 문제들을 쉽게 해결할 수 있게 되었지만, 일반 사용자의 하드웨어로는 완전한 파인 튜닝이 불가능해졌다. 또한 각 다운스트림 태스크에 대해 파인 튜닝된 모델을 저장하고 배포하는 것은 많은 비용이 든다. 왜냐하면 파인 튜닝된 모델은 원래 사전 학습 모델과 크기가 동일하기 때문이다. PEFT는 두 가지 문제를 모두 해결하기 위한 방법을 제시한다.
PEFT 접근 방식은 사전 학습된 LLM의 대부분의 파라미터를 동결하면서 소수의 모델 파라미터(ex. 0.01%)만 파인 튜닝하므로 계산 및 저장 비용이 크게 절감되며 이는 LLM의 파인 튜닝 중에 발생하는 catastrophic forgetting를 극복하기도 한다. (미리 학습된 Pretrained weights는 고정된 상태로 유지되기 때문에)
또한 각 다운스트림 데이터 세트에 대해 발생하는 체크포인트는 몇 MB에 불과하면서도 full fine-tuning에 필적하는 성능을 달성할 수 있다. 학습된 작은 가중치는 사전 학습된 LLM에 추가되기 때문에 전체 모델을 교체할 필요 없이 작은 가중치를 추가하여 동일한 LLM을 여러 작업에 사용할 수 있다.
현재 PEFT를 위한 다양한 방법론들이 연구되고 있으며, 그 중 가장 유명한 것 중 하나가 Stable diffusion이나 LLaMA, Alpaca에도 많이 적용되는 Microsoft에서 공개한 LoRA이다.
LoRA
Introduction
전이 학습이 시작된 이래로 수십 개의 연구에서 model adaptation의 파라미터 및 컴퓨팅 효율성을 높이기 위해 노력해왔었다. 대표적인 방법은 어댑터 레이어를 추가하거나 입력 레이어 activation을 optimizing하는 것이다. 하지만 두 방법 모두 latency에 민감한 대규모 프로덕션에는 한계가 있었다.
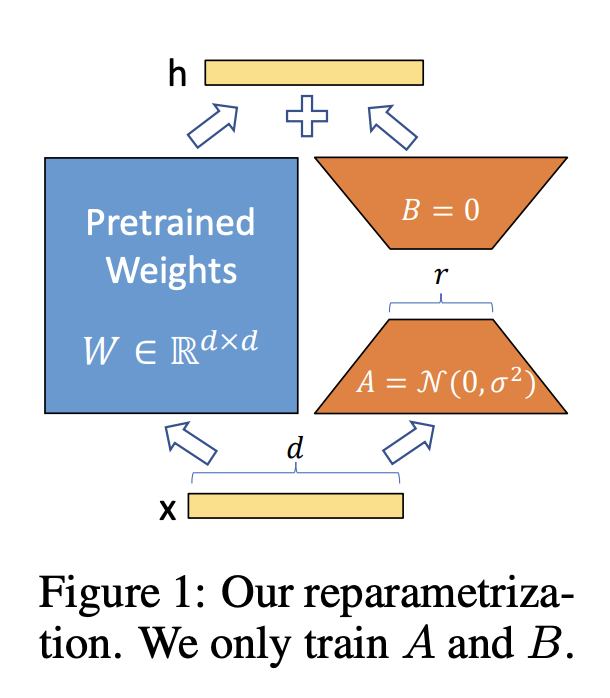
LoRA는 GPT-3와 같은 거대 모델들이 over-parametrize 되있으며, 실제 다운스트림 태스크를 해결하는 데 필요한 정보는 일부이며, 이 정보는 low intrinsic dimension에 있을거라는 연구에서 영감을 얻어서 시작되었다.
LoRA를 사용하면 위 그림과 같이 사전 학습된 가중치를 고정된 상태로 유지하면서 오른쪽의 dense layer만 학습하는데, dense layer의 weight를 low-rank로 decomposition한 matrices만을 optimizing하는 방식이다. 그래서 위 Figure 1과 같이 파인 튜닝 시에는 pre-trained weights \(W\)는 freeze하고, low-rank decomposition된 weights \(A\), \(B\)만 학습하여 W에 summation하게 된다.
LoRA를 사용하면 다음과 같은 이점이 있다.
- 사전 학습된 모델을 공유하면서 다양한 태스크를 위한 여러 개의 작은 LoRA 모듈을 구축하는 데 사용할 수 있다. pre-trained weights(\(W_0\))을 고정하고 Figure 1의 행렬 A와 B만 A’, B’로 교체하면 되기 때문에 스토리지 요구 사항과 task-switching 오버헤드를 크게 줄일 수 있다.
- 다운스트림 태스크마다 파인 튜닝을 모두 다시 해야하는 다른 모델들 대비 LoRA를 사용하면 low-rank matrices만 최적화하면 되기 때문에, 학습 효율을 높이고 하드웨어 진입 장벽을 최대 3배까지 낮출 수 있다.
- 배포 시 훈련 가능한 행렬을 pre-trained weights(\(W_0\))와 병합할 수 있으므로, fully fine-tuned 모델에 비해 inference latency가 발생하지 않는다.
- GPT-3의 경우 12,888에 해당하는 원본(full-rank)정보를 r = 1, 2 정도의 매우 낮은 rank에서도 표현 가능하다는 것을 밝혔다.
Problem Statement
LoRA는 dense layer가 존재하는 모든 신경망에 적용이 가능하지만, 여기서는 language modeling에 초점을 맞추고 있다.
먼저 \(\Phi\) 로 parameterize 되어있는 pretrained autoregressive language model \(P\Phi(y|x)\) 이 주어졌다고 가정한다. \(P\Phi(y|x)\) 는 GPT와 같은 일반적인 multi-task learner일 수 있다.
Adaptation을 위해 각 다운스트림 태스크는 컨텍스트 - 타켓 쌍의 훈련 데이터셋 집합 \(Z = {{(x_i, y_i)}}{i=1,..,N},\) 로 표현되며, 여기서 \(x_i\)와 \(y_i\)는 모두 토큰 시퀀스이다.
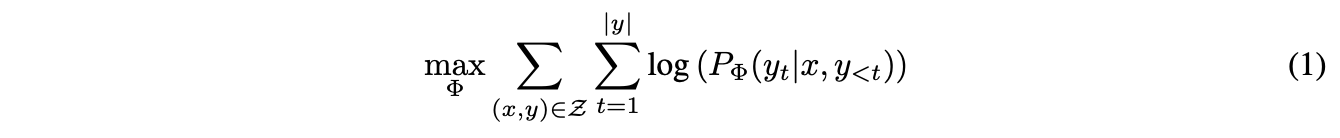
full fine-tuning의 경우 위처럼 모델은 pretrained weights \(Phi_0\) 으로 초기화되고 conditional language modeling objective를 최대화하기 위해 기울기를 반복적으로 \(\Phi_0 + \triangle\Phi\)로 업데이트한다.
full fine-tuning의 주요 단점 중 하나는 각 다운스트림 태스크마다 \(|\Phi_0|\)과 같은 차원의 크기를 가진 \(|\triangle\Phi|\)를 재학습해야 한다는 점이다. 따라서 사전 학습된 모델이 큰 경우(예: \(|\Phi_0|\) ≈ 175억인 GPT-3), 파인 튜닝된 모델의 많은 인스턴스를 저장하고 배포하는 데에 어려움이 있다.
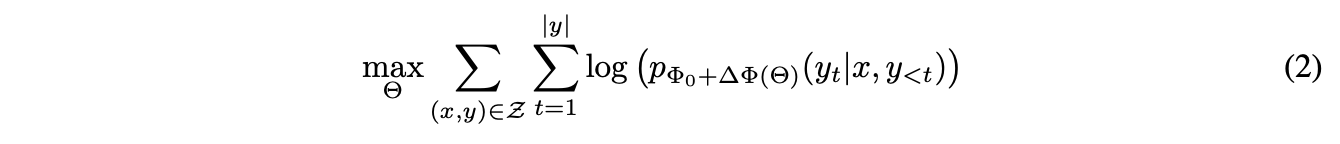
LoRA는 업데이트 해야하는 task-specific parameter를 \(\triangle\Phi = \triangle\Phi(\Theta)\) 와 같이 더 작은 크기의 매개변수 \(\Theta\)로 인코딩하는 보다 효율적인 접근 방식을 채택한다 (\(\Theta \ll \Phi_0\)).
따라서 \(|\triangle\Phi|\)를 찾는 작업은 \(\Theta\)에 대한 최적화로 대체된다.
위와 같은 방식으로 GPT-3를 fine-tuning할 경우, 학습해야 할 파라미터 \(|\Theta|\)의 수는 \(|\Phi_0|\)의 0.01%만큼 줄어들 수 있다.
Our Method
LOW-RANK-PARAMETRIZED UPDATE MATRICES
신경망에는 행렬 곱셈을 수행하는 많은 dense layer가 있으며, 이러한 계층의 가중치 행렬은 일반적으로 full-rank를 갖는다. 하지만 LoRA는 Aghajanyan et al. (2020)에 착안하여 adaptation 과정에서 low intrinsic rank를 가진 가중치로 업데이트하는 방법이다.
먼저 pretrained weights matrix \(W_0 ∈ R^{d\times k}\)에 대해 \(W_0 + ∆W = W_0 + BA\)로 업데이트한다. 즉, \(W_0\)는 동결하고 low-rank로 decomposition된 \(B ∈ R^{d\times r}\)와 \(A ∈ R^{r\times k}\)만을 학습한다. 그리고 \(W_0\)와 \(∆W = BA\) 모두 동일한 input에 곱해지며, 각각의 출력 벡터는 coordinate-wise로 합산된다.
forward pass 산출식은 다음과 같다.
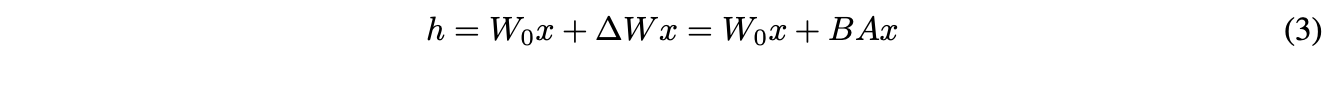
A는 random Gaussian initialization, B는 0으로 초기화되므로 훈련이 시작될 때 \(∆W = BA\)는 0이 된다. 그런 다음 \(∆W x\)를 \(a \over r\)로 스케일링한다. Adam으로 최적화할 때 \(a\)를 조정하는 것은 학습 속도를 조정하는 것과 거의 동일하다고 한다. 따라서 \(a\)를 처음 \(r\) 값으로 설정하고 스케일링은 \(r\)을 변경할 때 하이퍼파라미터를 재조정할 필요성을 줄이는 데 도움이 된다.
A Generalization of Full Fine-tuning
LoRA는 rank \(r\)을 pre-trained weights 행렬의 rank로 설정하여 full fine-tuning의 표현력을 회복하거나 조정할 수 있다. 따라서 r을 늘릴수록 LoRA 학습은 대략 원래 모델을 학습하는 것으로 수렴하는 반면, 어댑터 기반 방식은 MLP로, 접두사 기반 방식은 긴 입력 시퀀스를 사용할 수 없는 모델로 수렴한다.
No Additional Inference Latency
프로덕션에 배포할 때에는 \(W = W_0 + BA\)를 명시적으로 계산하여 저장하고 평소와 같이 추론을 수행할 수 있다. 만약 다른 다운스트림 태스크로 전환해야 하는 경우, \(BA\)를 뺀 다음 다른 \(B’A’\)을 추가하면 되기 때문에, 메모리 오버헤드가 거의 없으며, 이렇게 하면 태스크별로 파인 튜닝된 모델에 비해 추론하는 동안 추가 지연 시간이 발생하지 않는다.
APPLYING LORA TO TRANSFORMER
LoRA는 dense layer가 존재하는 모든 신경망에 적용 가능하지만, 논문에서는 단순성과 파라미터 효율성을 위해 트랜스포머 아키텍처에서 attention weights만 조정하고 MLP 모듈을 동결하였다. (논문에서는 \(W_q\), \(W_v\)만 사용)
Practical Benefits and Limitations
LoRA의 가장 큰 이점은 메모리 및 스토리지 사용량 감소에서 비롯된다. Adam으로 학습된 대형 트랜스포머의 경우, 고정된 파라미터에 대한 최적화 상태를 저장할 필요가 없으므로 VRAM 사용량을 최대 2/3까지 줄일 수 있다. GPT-3 175B에서는 훈련 중 VRAM 소비량을 1.2TB에서 350GB로 줄였다고 한다.
또한, \(r = 4\)이고 \(W_q\), \(W_v\) 행렬에만 LoRA를 적용할 때 체크포인트 크기가 약 10,000배(350GB에서 35MB로) 줄어들며, 대부분의 파라미터에 대한 기울기를 계산할 필요가 없기 때문에 GPT-3 175B에서 훈련하는 동안 전체 파인 튜닝에 비해 25%의 속도 향상을 관찰할 수 있었다.
하지만 LoRA에도 한계점이 있는데, LoRA를 적용할 weight matrices를 선택할 때 대부분 휴리스틱에 의존하기 때문에 조금 더 원칙적인 방법이 필요하다고 한다.
Empirical Experiments
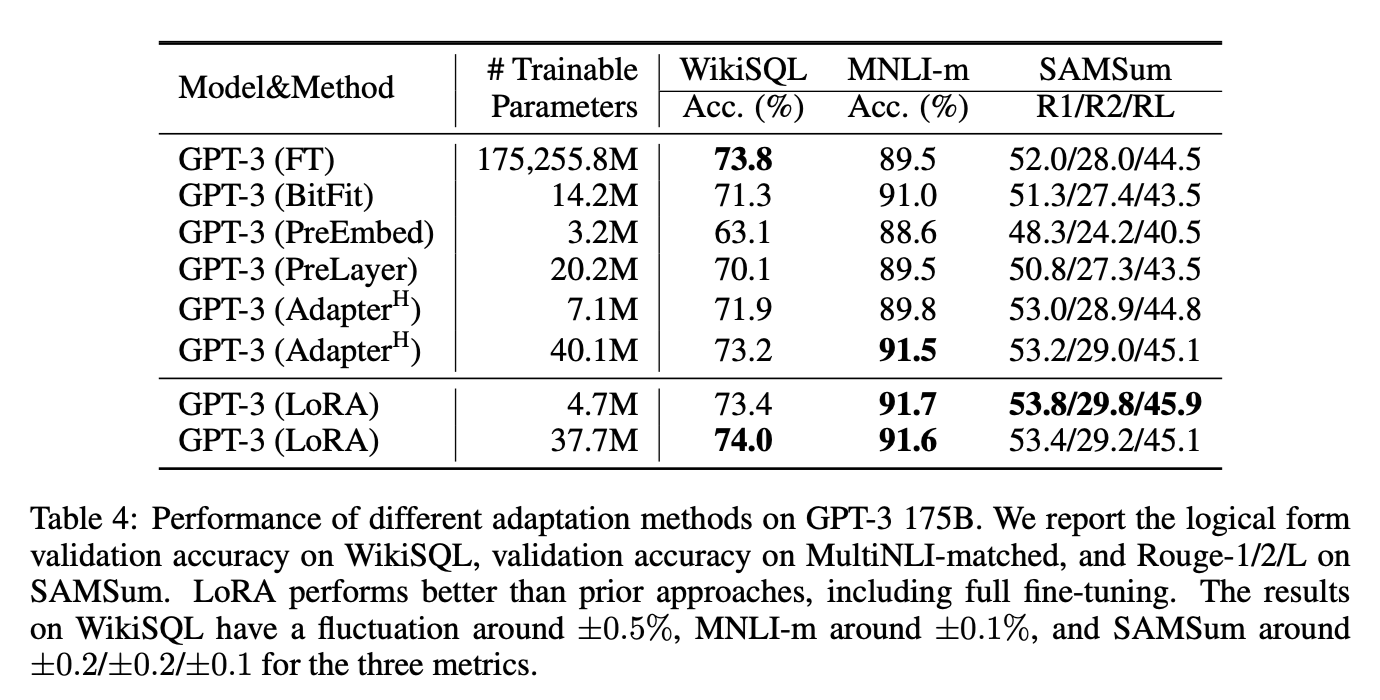
LoRA에 대한 최종 테스트로 GPT-3 175B 모델을 사용하였고, 위의 표에서 볼 수 있듯이 세 가지 데이터 셋 모두에서 파인 튜닝 모델의 베이스라인과 일치하거나 이를 초과하는 모습을 볼 수 있다.
Using PEFT with Huggingface
LLaMA의 변형인 Alpaca에도 LoRA가 적용된 오픈소스 프로젝트들이 공개되고 있다.
HuggingFace의 PEFT 라이브러리를 이용하면 LoRA를 쉽게 적용해볼 수 있으며, 지원하는 PEFT 기법과 태스크들은 다음과 같다.
class PeftType(str, enum.Enum):
PROMPT_TUNING = "PROMPT_TUNING"
MULTITASK_PROMPT_TUNING = "MULTITASK_PROMPT_TUNING"
P_TUNING = "P_TUNING"
PREFIX_TUNING = "PREFIX_TUNING"
LORA = "LORA"
ADALORA = "ADALORA"
ADAPTION_PROMPT = "ADAPTION_PROMPT"
IA3 = "IA3"
LOHA = "LOHA"
LOKR = "LOKR"
class TaskType(str, enum.Enum):
SEQ_CLS = "SEQ_CLS"
SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM"
CAUSAL_LM = "CAUSAL_LM"
TOKEN_CLS = "TOKEN_CLS"
QUESTION_ANS = "QUESTION_ANS"
FEATURE_EXTRACTION = "FEATURE_EXTRACTION"
LoRA의 적용은 다음과 같이 매우 간단하게 할 수 있다.
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=8, # LoRA의 dimension (rank 수) : 논문에서는 4를 사용
lora_alpha=32, # learning_rate와 유사함. feed-forward 할 때 얼마나 반영할 지
lora_dropout=0.1, # LoRA 레이어의 드롭아웃 확률
target_modules=["q", "v"], # LoRA를 적용할 self-attention 모듈
bias="none", # 훈련 중 bias 업데이트 할 지 유무 ["none", "all", "lora_only"]
task_type="SEQ_2_SEQ_LM", # 본인의 태스크에 맞는 타입을 명시하면 됨
)
model = get_peft_model(model, lora_config)
LLaMA와 같은 foundation 모델과 더불어 LoRA와 같은 PEFT 기법을 활용해서 거대 언어 모델을 개인이 쉽게 파인 튜닝해보고 사용해볼 수 있는 시대가 빠르게 다가오고 있는 것 같다.