[리뷰] A Survey of Efficient LLM Inference Serving
Zhen, Ranran, et al. “Taming the Titans: A Survey of Efficient LLM Inference Serving.” arXiv preprint arXiv:2504.19720, 2024. [paper]
1. Introduction
2. LLM Inference Serving in Instance
- 2.1 Model Placement
- 2.2 Request Scheduling
- 2.3 Decoding Length Prediction
- 2.4 KV Cache Optimization
- 2.5 PD Disaggregation
3. LLM Inference Serving in Cluster
4. Emerging Scenarios
5. Future Works
6. Conclusion
최근 오픈소스 LLM들이 빠르게 발전하며 모델 아키텍처와 기능이 지속적으로 업데이트되고 있으며, 이에 대한 수요 또한 급증하고 있다. 하지만 LLM의 방대한 매개변수와 어텐션 메커니즘은 메모리 및 컴퓨팅 자원에 큰 부담을 주어, 추론 서비스 시 낮은 지연 시간과 높은 처리량 달성을 어렵게 만든다. 이러한 어려움은 서비스 수준 목표(SLO; Service Level Objectives)를 충족하기 위한 추론 서비스 최적화 연구를 촉진시켰다.
본 논문은 LLM 추론 서비스의 최적화 방법들을 인스턴스 수준, 클러스터 규모 전략, 새로운 시나리오 및 기타 중요 영역으로 계층화하여 체계적으로 조사하며, 기존 연구들의 한계를 보완하여 최첨단 방법론에 대한 세분화된 분류를 제공하고 미래 연구 방향을 제시하고자 한다.
1. Introduction
이 논문은 그림 1과 같이 LLM 추론 서비스 최적화 방법들을 다음과 같이 분류하여 설명한다.
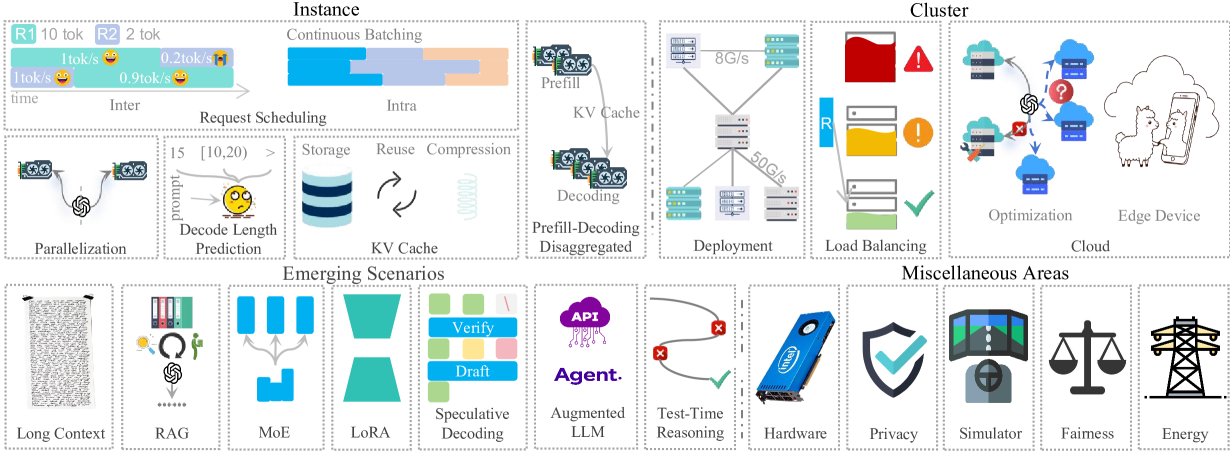
- 인스턴스 수준 최적화 (Instance-Level optimization):
- Model placement: 단일 GPU 메모리 부족 시 여러 장치에 모델 매개변수 분산
- Request scheduling 및 Decoding length prediction: 짧은 요청을 우선 처리하여 전체 지연 시간 감소 (동적 일괄 처리 중 요청 삽입/제거 관리 포함)
- KV cache: 중복 계산 완화 (But, 저장 효율성, 재사용 전략, 압축 문제가 여전히 있음)
- Disaggregated architecture: 프리필(prefill) 단계와 디코딩 단계를 분리하여 각 단계별 최적화 진행
- 클러스터 수준 최적화 (Cluster-Level optimization):
- Deployment strategies: 비용 효율적인 GPU 클러스터 구성 (이기종 하드웨어 활용 포함), 서비스 지향 클러스터 스케줄링
- Load Balancing: 분산된 인스턴스 간 리소스 부족 또는 과부하 방지
- Cloud-based LLM Serving: 로컬 인프라 부족 시 클라우드 활용, 동적 LLM 서비스 수요 충족을 위한 확장
- 새로운 시나리오 (Emerging Scenarios):
- Long Context processing
- 특정 기술 및 모듈: 검색 증강 생성(RAG, Retrieval-Augmented Generation), Mixture-of-Experts(MoE), LoRA(Low-Rank Adaptation), 추측 디코딩(Speculative Decoding), Augmented LLMs, Test-Time Reasoning
2. LLM Inference Serving in Instance
이 섹션에서는 그림 2와 같이 배포, 스케줄링, 디코딩 길이 예측, 메모리 관리 및 혁신적인 아키텍처를 다룬다.

2.1 Model Placement
LLM의 방대한 파라미터 수는 단일 GPU의 용량을 초과하는 경우가 많아, 모델을 여러 GPU에 분산하거나 CPU 메모리 혹은 스토리지로 일부를 옮기는(오프로딩) 전략이 필수적이다. 주요 접근 방식은 다음과 같다.
- 모델 병렬 처리 (Model Parallelism): 모델 자체를 여러 GPU에 나누어 처리
- 파이프라인 병렬 처리 (Pipeline Parallelism):
- 개념: 모델의 레이어를 여러 GPU에 걸쳐 순차적으로 분산한다. 이를 통해 데이터가 파이프라인처럼 각 GPU를 거치며 처리되어, 순차적인 데이터의 동시 처리가 가능해지고 훈련/추론 속도가 향상된다.
- ex. GPipe, PipeDream, Megatron-LM (Narayanan et al.,2021)
- 텐서 병렬 처리 (Tensor Parallelism):
- 개념: 개별 연산 또는 레이어를 여러 장치에서 병렬로 계산되는 더 작은 하위 텐서로 분할하여 계산 효율성을 높이고 더 큰 모델 크기를 가능하게 한다.
- ex. Megatron-LM (Shoeybi et al., 2020)
- 기타 특화된 병렬 처리 기술:
- 시퀀셜 병렬 처리 (Sequential Parallelism): 긴 컨텍스트 처리 시, LayerNorm 및 Dropout 같은 활성화 함수를 시퀀스 차원을 따라 분할한다.
- 컨텍스트 병렬 처리 (Context Parallelism): 모든 레이어를 시퀀스 차원을 따라 분할하여 시퀀셜 병렬 처리를 확장한다.
- 전문가 병렬 처리 (Expert Parallelism): sparse MoE 모델의 경우, 전문가 모듈(sparse MoE 컴포넌트)을 GPU에 할당하여 메모리 사용량을 최적화한다.
- 파이프라인 병렬 처리 (Pipeline Parallelism):
- 오프로딩 (Offloading)
- 개념: 모델 가중치의 대부분을 CPU 메모리나 스토리지 장치에 저장하고, 추론 시 필요한 부분만 GPU 메모리로 로드하여 처리
- 주요 기술:
- ZeRO-Offload, DeepSpeed-Inference, FlexGen: 모델 가중치의 대부분을 메모리 또는 스토리지 장치에 저장하고 필요시 GPU로 로드하는 일반적인 오프로딩 기법이다.
- PowerInfer: GPU-CPU 하이브리드 엔진을 사용하여, 자주 사용되는 ‘핫 뉴런’은 GPU에 미리 로드하여 속도를 높이고, 덜 사용되는 ‘콜드 뉴런’은 CPU에서 계산하여 GPU 메모리 요구 사항과 데이터 전송량을 줄인다.
- TwinPilots: GPU와 CPU를 트윈 컴퓨팅 엔진으로 통합하고, GPU 및 CPU 메모리를 모두 포함하는 계층적 메모리 아키텍처를 사용하는 새로운 컴퓨팅 패러다임을 제안한다 (비대칭 다중 처리 프레임워크 내).
- Park and Egger (2024): 동적이고 세밀하게 조정된 워크로드 할당을 통해 GPU와 CPU 간의 효율적인 리소스 활용 기술을 제안한다.
2.2 Request Scheduling
요청 스케줄링은 LLM 추론 서비스의 대기 시간 최적화에 직접적인 영향을 미치며, 요청 간(inter-request) 스케줄링과 요청 내(intra-request) 스케줄링 관점에서 관련 알고리즘을 살펴본다.
- 요청 간 스케줄링 (Inter-Request Scheduling):
- 목표: 여러 요청이 몰릴 때 실행 순서를 정하고 배치 내 요청의 우선순위를 결정
- FCFS(First-Come-First-Served): 대부분의 현재 LLM 솔루션은 선입선출(FCFS) 방식을 사용하나, 이는 먼저 온 긴 요청 때문에 짧은 요청의 처리가 지연되어 전체 대기 시간을 증가시키는 문제(Head-of-Line blocking)가 있다.
- 최적화 방향: 짧은 요청에 우선순위를 부여하여 해당 요청의 서비스 수준 목표(SLO) 달성을 목표로 함
- 주요 기술 및 시스템 (디코딩 길이 예측 활용):
- FastServe: Skip-Join MLFQ(Multi-Level Feedback Queue) 스케줄러를 사용. 우선순위 높은 요청을 먼저 처리하고, 오래 대기한 요청은 우선순위를 높이며, 긴 작업을 선점하여 짧은 요청을 가속화한다.
- Fu et al. (2024c): 예측된 디코딩 시간이 짧은 요청에 우선순위를 부여하여 최단 작업 우선 스케줄링(SJF, Shortest Job First) 방식을 근사한다.
- Shahout et al. (2024b): 남은 디코딩 길이를 동적으로 예측하고 긴 요청의 과도한 선점을 방지하기 위해 선점 비율을 도입하여 최단 잔여 시간 우선 스케줄링(SRTF, Shortest Remaining Time First) 방식을 개선한다. (단, 디코딩 길이 예측 모델 호출 오버헤드가 발생할 수 있음)
- Prophet: PD(Prefill-Decoding) 분리 아키텍처를 활용, 프리필 단계에서는 SJF를, 디코딩 단계에서는 Skip-Join MLFQ를 적용한다.
- INFERMAX: 추론 비용 모델 기반의 전략적 선점이 비선점 방식보다 GPU 비용을 줄일 수 있음을 보여준다.
- 대조적 접근:
- BatchLLM: 개별 요청 순서보다는 전역 공유(global sharing)를 통해 요청 처리 자체를 우선시한다.
- 요청 내 스케줄링 (Intra-Request Scheduling):
- 목표: 동시에 처리되는 요청 배치의 스케줄링을 통해 요청 도착, 완료 시간, 출력 길이의 가변성을 해결하여 병렬 디코딩 효율성을 향상시킨다.
- 주요 기술 및 시스템:
- Orca: 반복 수준 스케줄링(iteration-level scheduling)을 도입하여 반복마다 요청을 동적으로 추가/제거할 수 있게 하여 유연성을 높인다.
- Dynamic SplitFuse & chunked-prefills: 프리필 단계를 더 작은 세그먼트로 나누고 이를 디코딩 단계와 병합하여 긴 프롬프트로 인한 지연을 줄이고 프리필 중 디코딩 중단을 방지한다.
- SCLS (slice-level scheduling): 최대 생성 길이를 고정된 크기의 슬라이스(slice)로 나누어 순차적으로 처리함으로써 서비스 시간과 메모리 사용량을 정밀하게 제어한다.
2.3 디코딩 길이 예측 (Decoding Length Prediction)
생성될 출력 길이의 불확실성이 요청 스케줄링을 복잡하게 만드는 문제를 해결하기 위해 최근 연구들이 세 가지 주요 접근 방식으로 진행되고 있다.
- 정확한 길이 예측 (Exact Length Prediction):
- 목표: 생성될 정확한 토큰 수를 예측한다.
- 방법: BERT 임베딩과 랜덤 포레스트 회귀 모델, 작은 OPT 모델(Hu et al.), 또는 더 간단한 회귀 모델(Qiu et al.) 등을 사용한다.
- 범위 기반 분류 (Range-Based Classification):
- 목표: 요청을 미리 정의된 길이 구간(bin)으로 분류한다.
- 방법: Supervised fine-tuning을 하거나, DistilBERT 분류기, short/medium/long 구간 분류, BERT의 CLS 토큰을 FFN으로 처리하여 백분위수 그룹으로 분류(µ-Serve), 토큰 임베딩에 대한 경량 분류기 등을 사용한다.
- 상대적 순위 예측 (Relative Ranking Prediction):
- 목표: 요청들 간의 상대적인 길이 순서를 예측한다.
- 방법: 회귀, 분류, 쌍별(pairwise) 비교 방법, 또는 입력 요청만으로 배치 내 상대적 관계 예측을 통해 견고성을 높이고 과적합을 줄인다.
- 특징: 배치 내 요청 순서 결정에만 필요하므로 직관적이지만, 일부 요청이 다음 배치로 넘어가면 순위를 다시 계산해야 하는 오버헤드가 발생할 수 있다. (다른 두 방법은 이 문제가 없음)
2.4 KV Cache Optimization
KV 캐시는 어텐션 메커니즘에서 이전에 계산된 Key와 Value 값을 저장하여 추론 시간 복잡도를 줄이는 데 핵심적이지만, 메모리 관리, 계산 재사용, 압축 효율성에서 여러 문제를 야기한다.
- 메모리 관리 (Memory Management):
- 무손실 저장 기술 (Lossless Storage Techniques):
- PagedAttention & vLLM: OS에서 영감을 받은 페이징 기법을 도입하여 메모리 단편화를 해결하고 공간 낭비를 최소화한다.
- DistAttention: 긴 컨텍스트 처리를 위해 분산된 KV 캐시 처리를 제안한다.
- FastDecode: 분산 처리를 통해 캐시를 CPU 메모리로 오프로드한다.
- LayerKV: 계층별로 KV 캐시를 할당하고 오프로드한다.
- KunServe: 다른 인스턴스의 파이프라인 메커니즘을 통해 모델 파라미터를 제거하여 캐시 공간을 확보한다.
- SYMPHONY: 다중 턴(multi-turn) 대화 패턴을 활용하여 캐시를 동적으로 마이그레이션한다.
- InstCache: LLM 기반 명령어 예측을 통해 응답성을 향상시킨다.
- 근사 방법 (Approximation Methods):
- PQCache: 임베딩 검색에 사용되는 low-overhead Product Quantization을 활용하여 임베딩을 하위 임베딩으로 분할하고 클러스터링을 적용하여 계산 오버헤드를 줄인다.
- InfiniGen: 주요 KV 캐시 항목의 지능적인 프리페칭을 통해 데이터 전송 오버헤드를 줄이고 성능을 향상시키는 동적 캐시 관리 프레임워크이다.
- 무손실 저장 기술 (Lossless Storage Techniques):
- 재사용 전략 (Reuse Strategies):
- 무손실 재사용 (Lossless Reuse):
- PagedAttention: 페이지 수준 관리를 통해 여러 요청 간 캐시 공유를 가능하게 한다.
- Radix tree-based system: 동적 노드 삭제를 통해 전역 prefix 공유를 구현한다.
- CachedAttention: 턴(turn) 간 캐시 재사용을 통해 대화에서 중복 계산을 최소화한다.
- 의미론적 인식 재사용 (Semantic-aware Reuse):
- GPTCache: 의미론적 유사성을 사용하여 LLM 출력을 캐싱하고 재사용한다.
- SCALM: 쿼리를 클러스터링하여 의미 있는 의미적 패턴을 찾아낸다.
- 무손실 전략은 법률, 의료, 코드 생성 등 정확한 템플릿 입력에 이상적이며, 의미론적 인식 전략은 일반적인 대화에 더 적합하다.
- 무손실 재사용 (Lossless Reuse):
- 압축 기술 (Compression Techniques): 추론 성능에 미치는 영향을 최소화하면서 메모리 사용량을 줄이기 위해 텐서 양자화 및 컴팩트 표현과 같은 가중치 및 캐시 압축 기술을 사용한다.
- 양자화 기반 압축 (Quantization-based Compression): 높은 비트 정밀도에서 낮은 비트 정밀도로 전환하여 메모리를 줄인다.
- FlexGen: 그룹별 양자화(Group-wise Quantization)를 사용하여 추가 I/O 비용 없이 KV 캐시를 4비트로 압축한다.
- Kivi: 캐시에 대한 채널별/토큰별 양자화를 제안한다.
- MiniCache: 인접 레이어 간 KV 캐시 상태의 높은 유사성을 활용하여 레이어 간 캐시를 압축한다.
- AWQ: 중요하지 않은 가중치를 양자화하면 양자화 손실이 줄어든다는 점을 활용한다.
- Atom: 혼합 정밀도, 세분화된 그룹/동적 활성화/캐시 양자화를 사용한다.
- QServe: 알고리즘-시스템 공동 설계를 통해 LLM을 W4A8KV4 정밀도로 양자화하여 GPU 배포 효율성을 향상시킨다.
- 컴팩트 인코딩 아키텍처 (Compact Encoding Architectures): 기존의 큰 행렬 대신 더 작은 행렬 표현을 사용한다.
- CacheGen: 사용자 정의 텐서 인코더를 사용하여 KV 캐시를 컴팩트한 bitstream으로 압축하여 디코딩 오버헤드를 최소화하면서 대역폭을 절약한다.
- 양자화 기반 압축 (Quantization-based Compression): 높은 비트 정밀도에서 낮은 비트 정밀도로 전환하여 메모리를 줄인다.
2.5 PD Disaggregation
프리필/디코딩(PD) 분리는 연산 집약적인 컨텍스트 인코딩과 메모리 집약적인 토큰 생성 단계를 서로 다른 최적화 환경으로 분리하여 LLM 추론의 연산 불균형 문제를 해결하는 접근 방식이다.
- DistServe: 각 단계(프리필, 디코딩)에 대한 리소스 할당 및 병렬 처리를 최적화하고, 대역폭 기반의 전략적 배치를 통해 통신 오버헤드를 최소화한다.
- Splitwise: 비용, 처리량, 전력 최적화를 위해 동종 및 이기종 장치 설계를 탐색한다.
- DéjàVu: 마이크로배치 스와핑 및 상태 복제를 통해 양방향 지연 시간, GPU 과잉 프로비저닝, 느린 복구로 인해 발생하는 파이프라인 버블(유휴 상태)을 해결한다.
- Mooncake: KV 캐시 중심의 분산 아키텍처를 사용하여 유휴 CPU, DRAM, SSD 리소스를 분산된 KV 캐시 스토리지에 활용하고, 높은 부하 시에는 조기 거부(early rejection)를 통해 낭비를 줄인다.
- TetriInfer: 디코딩 핫스팟(특정 부분에 부하 집중)을 피하기 위해 리소스 예측을 사용하는 2단계 스케줄링 알고리즘을 사용한다.
- P/DServe: 세분화된 프리필/디코딩 구성, 동적 조정, 온디맨드 요청 할당, 효율적인 캐시 전송을 통해 LLM 배포 문제를 해결한다.
3. LLM Inference Serving in Cluster
이 섹션에서는 그림 3과 같이 여러 장비로 구성된 클러스터 환경에서 LLM 추론 서비스의 효율적 제공을 위한 클러스터 수준 배포/스케줄링 전략과 클라우드 기반 클러스터 서비스 최적화 방안을 다룬다.
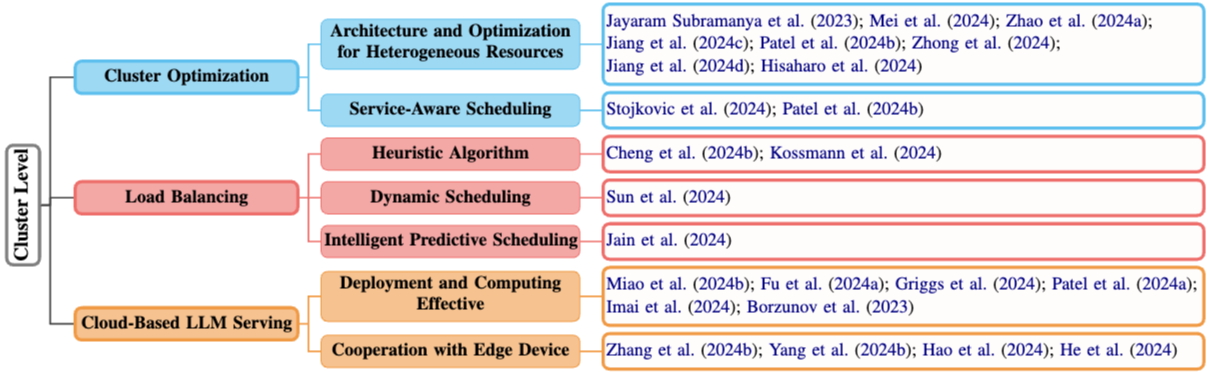
3.1 클러스터 최적화 (Cluster Optimization)
LLM의 대규모화로 인해 단일 머신의 한계를 극복하기 위한 클러스터 환경이 필수가 되었으며, 유연성과 비용 효율성을 위해 이기종 머신(heterogeneous machines) 활용이 핵심 과제로 부상하면서 내부 최적화(이기종 자원 활용)와 외부 최적화(서비스 지향 클러스터 스케줄링)의 통합적 접근이 요구되고 있다.
- 이기종 자원을 위한 아키텍처 및 최적화 (Architecture and Optimization for Heterogeneous Resources): 다양한 성능과 특성을 가진 하드웨어(주로 GPU)를 효과적으로 통합하고 활용하는 내부 최적화 전략
- 적응형 작업 할당: 다양한 GPU 유형 및 배치 크기에 맞춰 작업을 동적으로 할당하여 정적 구성 대비 처리량을 크게 향상시킨다 (Jayaram Subramanya et al.).
- 이기종 환경 모델링 및 실행 최적화:
- Helix: 이기종 GPU 및 네트워크 환경에서 LLM 서비스 실행을 방향성 가중 그래프의 최대 흐름 문제로 모델링한다. 여기서 노드는 GPU 인스턴스를, 엣지는 용량 제약을 통해 GPU 및 네트워크의 이질성을 인코딩하여 최적의 실행 경로를 찾는다.
- LLM-PQ: 이기종 GPU 클러스터에 맞춰 적응형 양자화 및 GPU의 물리적 연결 구조(위상)를 인식하는 파티션(분할) 방식을 제안한다.
- HexGen: 컴퓨팅 성능이 서로 다른 GPU들에서 비대칭적인 병렬 실행을 지원한다.
- 이기종 분리 아키텍처 최적화: 프리필과 디코딩 단계를 분리하는 아키텍처를 이기종 환경에서 최적화
- Splitwise, DistServe, HEXGEN-2: 이기종 환경에서 분리된 아키텍처의 계산을 최적화한다. 특히 HEXGEN-2는 제약 조건 기반 스케줄링과 그래프 기반 리소스 최적화를 통해 LLM 서비스 제공에 중점을 둔다.
- 고급 하드웨어 통합: 고급 인터커넥트 기술, 고대역폭 메모리(HBM), 에너지 효율적인 전력 관리 시스템 등을 통합하여 전반적인 성능을 향상시킨다 (Hisaharo et al.).
- 서비스 인식 스케줄링 (Service-Aware Scheduling): 클러스터 전체의 서비스 관점에서 요청의 특성이나 목표를 고려하여 스케줄링하는 외부 최적화 전략. 이는 위에서 언급된 내부 최적화를 더욱 향상시킨다.
- 동적 자원 조정:
- DynamoLLM: 처리할 요청의 입력 및 출력 길이에 따라 서비스 인스턴스 수, 병렬 처리 수준, GPU 작동 주파수 등을 동적으로 조정하여 서비스 클러스터 전체를 최적화한다.
- 클러스터 수준의 분리 스케줄링:
- Splitwise: 프리필 단계와 디코딩 단계를 서로 다른 장치에서 실행하도록 클러스터 수준에서 스케줄링하는 방식을 제안한다.
- 동적 자원 조정:
3.2 로드 밸런싱 (Load Balancing)
클러스터 수준의 로드 밸런싱은 여러 노드에 요청을 적절히 분배하여 특정 노드의 과부하나 낮은 활용률을 방지하고, 이를 통해 전체 처리량과 서비스 품질을 향상시키는 것을 목표로 한다. 기존의 라운드 로빈이나 Random 방식 외에 더 정교한 기법들이 등장하고 있다.
- 휴리스틱 알고리즘 (Heuristic Algorithm):
- SCLS: max-min 알고리즘을 사용하여 워크로드를 분산한다. 예상 서비스 시간이 가장 긴 배치를 현재 부하(큐에 있는 모든 배치의 총 서비스 시간)가 가장 낮은 인스턴스에 할당한다.
- SAL: (1) 대기 중인 프리필 토큰 수와 (2) 사용 가능한 메모리라는 두 가지 요소를 기반으로 부하를 정량화하여, 부하가 가장 낮은 서버로 요청을 전달한다.
- 동적 스케줄링 (Dynamic Scheduling):
- Llumnix: 런타임 중에 모델 인스턴스 간에 요청을 동적으로 재스케줄링하여 요청의 이질성과 예측 불가능성에 대응한다. 실시간 마이그레이션을 통해 요청 및 메모리 상태를 전송하여, 부하가 증가할 경우 중간 작업을 가장 부하가 적은 인스턴스로 옮긴다.
- 지능형 예측 스케줄링 (Intelligent Predictive Scheduling):
- Jain et al.: 요청 라우팅을 Markov Decision Process(MDP)로 모델링하고 강화 학습을 사용하여 최적의 라우팅 정책을 학습한다. 응답 길이 예측, 워크로드 영향 평가, 강화 학습을 통합한다.
3.3 클라우드 기반 LLM 서비스 (Cloud-Based LLM Serving)
로컬 환경에서 LLM 배포에 필요한 리소스가 부족할 경우, 클라우드 서비스는 경제적인 대안을 제공한다. 최근 연구는 클라우드 배포 효율성 최적화와 엣지 장치와의 협력에 중점을 두고 있다.
- 배포 및 컴퓨팅 효율성 (Deployment and Computing Effectiveness):
- 스팟 인스턴스 활용: LLM 배포 비용 절감을 위해 중단 위험이 있는 스팟 인스턴스를 활용하며, 동적 재병렬화, 파라미터 재사용, 상태 저장 추론 복구 등으로 위험을 완화한다 (SpotServe).
- 서버리스 환경 최적화: 최적화된 체크포인트, 라이브 마이그레이션, 지역성(locality)을 고려한 스케줄링을 통해 서버리스 환경의 콜드 스타트 지연 시간을 해결한다 (ServerlessLLM).
- GPU 할당 최적화: 요청 패턴에 따라 GPU 할당을 최적화하여 비용을 절감한다 (Mélange).
- 전원 관리 및 지연 시간 예측: 전원 관리를 통해 효율성을 높이거나(POLCA), 추론 지연 시간을 예측하여 클러스터 관리를 향상시킨다 (Imai et al.).
- 유휴 리소스 통합: 인터넷으로 연결된 지리적으로 분산된 장치를 통해 유휴 리소스를 통합하여 활용한다 (Borzunov et al.).
- 엣지 장치와의 협력 (Cooperation with Edge Device):
- 클라우드-엣지 협력: 클라우드의 지연 시간 및 대역폭 한계 속에서 SLO를 충족하기 위해, 분산된 엣지 장치와 클라우드 서버 간의 협업을 활용한다 (EdgeShard).
- 개인화된 엣지 스케줄링: Multi-armed bandit 프레임워크를 사용하여 개인화된 엣지 스케줄링을 수행한다 (PreLLM).
- 엣지-클라우드 모델 통합 및 오프로딩: 메모리 제약을 해결하기 위해 작은 엣지 모델을 클라우드 LLM과 통합하거나(Hao et al.), 심층 강화 학습을 사용하여 효율적이고 지연 시간을 고려한 추론 작업을 엣지에서 클라우드로 오프로딩한다 (He et al.).
4. Emerging Scenarios
이 섹션에서는 그림 4와 같이 긴 컨텍스트 처리, 검색 증강 생성(RAG), 전문가 혼합(MoE) 모델과 같은 다양한 작업, 모델 아키텍처, 그리고 떠오르는 연구 분야에 대한 효율적인 서비스 제공 방법을 소개한다.
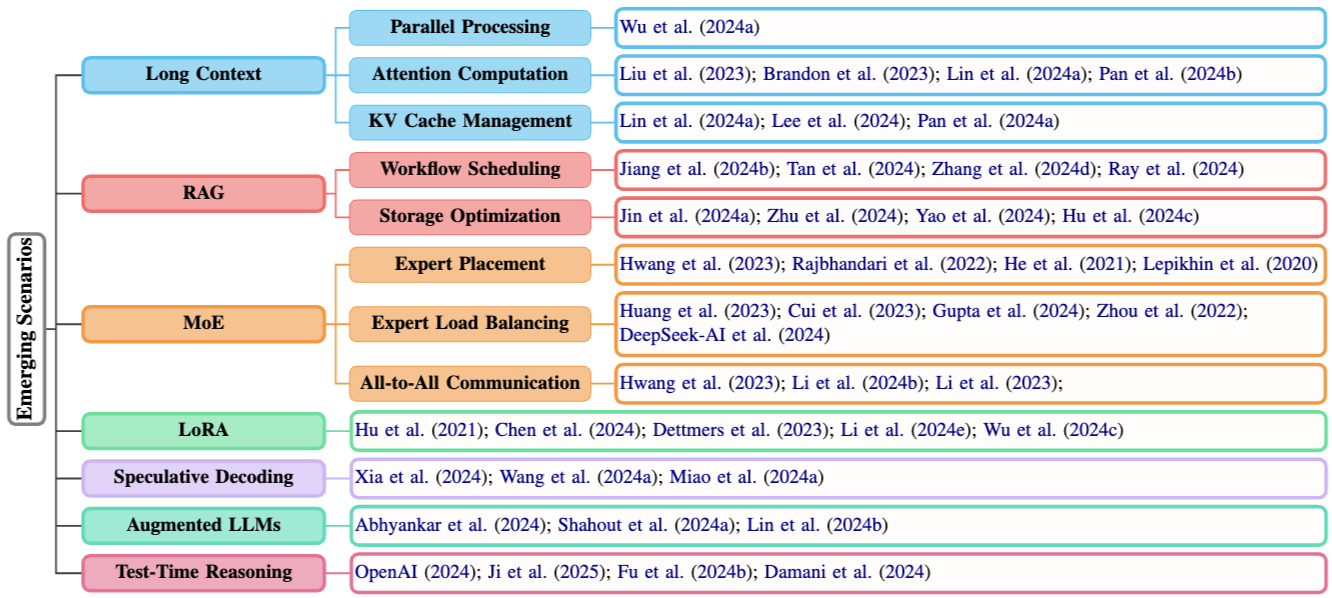
4.1 Long Context
LLM이 발전함에 따라 처리할 수 있는 컨텍스트의 길이가 수십만에서 수백만 토큰으로 크게 확장되었다. 이는 병렬 처리, 어텐션 계산 및 KV 캐시 관리에서 분산 배포, 연산 및 스토리지에 대한 새로운 기회와 함께 기술적 과제를 제시한다.
- 병렬 처리 (Parallel Processing)
- Loongserve: 효율적인 긴 컨텍스트 LLM 서비스를 위해 elastic sequence parallelism을 통해 성능을 향상시킨다.
- 어텐션 계산 (Attention Computation)
- RingAttention: 블록 단위(blockwise) 셀프 어텐션과 FFN 계산을 사용하여 긴 시퀀스를 여러 장치에 분산시키고, KV 통신과 어텐션 계산을 겹쳐서(overlapping) 수행한다.
- StripedAttention: RingAttention의 확장으로, 인과적 어텐션(causal attention)의 삼각형 구조로 인해 발생하는 계산 불균형 문제를 해결한다.
- DistAttention: 어텐션 계산을 여러 GPU에 걸쳐 세분화하여 디코딩 중 캐시 전송을 피하고, 최소한의 데이터 전송으로 임의 길이의 시퀀스에 대한 분할을 가능하게 한다.
- InstInfer: 어텐션 계산 및 관련 데이터를 연산 스토리지 드라이브(Computational Storage Drives)로 오프로드하여 KV 전송 오버헤드를 크게 줄인다.
- KV 캐시 관리 (KV Cache Management)
- Infinite-LLM: 클러스터 수준에서 캐시를 스케줄링하고, 리소스를 균형 있게 조정하며, 처리량을 최대화하여 동적인 LLM 컨텍스트를 관리한다.
- InfiniGen: 오프로딩 기반 시스템을 위해 CPU 메모리에서의 KV 캐시 관리를 최적화한다.
- Marconi: 하이브리드 모델에 맞춤화된 캐시 유입(admission) 및 방출(eviction) 정책을 도입하고, 계층별로 캐시 크기를 개인화하여 메모리 사용량을 크게 줄일 수 있음을 실험적, 이론적 분석을 통해 보여준다.
4.2 RAG
RAG는 LLM이 외부 지식을 검색하여 답변을 생성할 수 있게 해주지만, 검색 과정의 다양성과 복잡성으로 인해 대규모 검색 컨텍스트에서 지연 시간 및 KV 캐시 스토리지 최적화에 어려움이 있다.
- 워크플로 스케줄링 (Workflow Scheduling): RAG 워크플로의 효율성, 유연성, 최적화를 개선하기 위한 최근 혁신들이다.
- PipeRAG: 파이프라인 병렬 처리, 유연한 검색 간격, 성능 기반 품질 조정을 통해 효율성을 향상시킨다.
- Teola: LLM 워크플로를 임베딩, 인덱싱, 검색 등과 같은 데이터 흐름 노드로 모델링하여 정밀한 실행 제어를 가능하게 한다.
- RaLMSpec: 일괄 검증(batched verification)을 통한 추론적 검색(speculative retrieval)을 사용하여 서비스 오버헤드를 줄인다.
- RAGServe: 쿼리를 스케줄링하고 텍스트 청크, 합성 방법 등 RAG 구성을 조정하여 품질과 지연 시간의 균형을 맞춘다.
- 스토리지 최적화 (Storage Optimization): 대규모 KV 캐시를 처리하는 데 있어 효율적인 스토리지 관리가 RAG 시스템에 매우 중요하다.
- RAGCache: 지식 트리(knowledge trees)와 동적 추론적 파이프라이닝(dynamic speculative pipelining)을 사용하여 중복성을 줄인다.
- SparseRAG: 프리필링(pre-filling)과 선택적 디코딩(selective decoding)을 통해 관련 토큰에 집중하여 캐시를 효율적으로 관리한다.
- CacheBlend: 캐시를 재사용하고 고정된 비율에 따라 토큰을 선택하여 부분 업데이트를 위해 KV 값을 다시 계산함으로써 효율성을 높이고 지연 시간을 줄인다.
- EPIC: CacheBlend와 대조적으로, 정적 희소 계산(static sparse computation)을 통해 위치 독립적인 컨텍스트 캐싱을 도입하여 각 블록의 시작 부분에서 소수의 토큰만 다시 계산한다.
4.3 MoE
파라미터 희소성(parameter sparsity)으로 알려진 MoE 모델은 LLM에서 뛰어난 성능을 보이지만(ex. DeepSeek-V3, Mixtral 8x7B), 추론 시 지연 시간 문제로 전문가 병렬 처리, 로드 밸런싱, 그리고 전문가 간의 All-to-All 통신이 있다. Liu et al (2024b)이 이에 대한 포괄적인 최적화 연구를 제시하고 있다.
- 전문가 배치 (Expert Placement):
- Tutel: 추가 오버헤드 없이 전환 가능한 병렬 처리 및 동적 파이프라이닝을 도입한다.
- DeepSpeed-MoE: 전문가 병렬 처리와 전문가 슬라이싱(expert slicing)을 결합한다.
- 전문가 로드 밸런싱 (Expert Load Balancing): 불균형한 토큰 분포는 장치 활용률 저하를 유발한다.
- Expert Buffering: 활성화된 전문가를 GPU에 할당하고 나머지는 CPU에 할당하며, 과거 데이터를 사용하여 부하가 높은 전문가와 낮은 전문가를 짝지어 균형을 맞춘다.
- Brainstorm: 부하에 따라 GPU 단위를 동적으로 할당한다.
- Lynx: 활성화된 전문가 수를 적응적으로 줄인다.
- ExpertChoice: 전문가별로 상위 k개의 토큰을 선택하는 방식을 사용한다 (기존의 토큰별 상위 k 전문가 선택과 반대).
- DeepSeek-V3: 배포 통계를 사용하여 부하가 높은 전문가를 식별하고 주기적으로 복제하여 성능을 최적화한다.
- All-to-All 통신 (All-to-All Communication): 전문가 처리는 토큰을 해당 전문가에게 전달하고(dispatch) 처리된 결과를 다시 모으는(collect) 과정에서 All-to-All 교환을 포함한다.
- Tutel: 2D 계층적 All-to-All 알고리즘을 사용한다.
- Aurora: All-to-All 교환 중 토큰 전송 순서를 최적화한다.
- Lina: 가능한 경우 텐서 파티셔닝을 활용하고, 성능 향상을 위해 동시적인 All-Reduce 연산보다 All-to-All 연산을 우선시한다.
4.4 LoRA
LoRA는 작고 훈련 가능한 어댑터(adapter)를 사용하여 기존 LLM을 특정 작업에 효율적으로 적응시키는 기법이다.
- CaraServe: 모델 멀티플렉싱(여러 LoRA 모델을 한 GPU에서 서비스), CPU-GPU 협력, 랭크(rank) 인식 스케줄링을 통해 GPU 효율적이고 콜드 스타트 없이 SLO(서비스 수준 목표)를 만족하는 서비스를 지원한다.
- dLoRA: 어댑터를 기본 모델과 동적으로 병합(merge) 및 병합 해제(unmerge)하고, 작업자(worker) 복제본 간에 요청과 어댑터를 마이그레이션하여 유연성을 높인다.
4.5 Speculative Decoding
추측 디코딩은 더 작은 보조 LLM을 사용하여 먼저 여러 초안 토큰을 생성하고, 이를 원래의 큰 대상 LLM과 병렬로 검증하여 추론 속도를 높이는 기법이다. 이를 통해 품질 저하 없이 지연 시간과 비용을 줄일 수 있다.
- SpecInfer: 트리 기반의 추론적 추론(tree-based speculative inference)을 사용하여 더 빠른 분산 환경 및 단일 GPU 오프로딩 환경에서의 추론을 지원한다.
4.6 Augmented LLMs
LLM은 API 호출이나 에이전트(Agent)와 같은 외부 도구와 점점 더 통합되어 활용되고 있다.
- APISERVE: 외부 API 호출을 위한 GPU 리소스를 동적으로 관리한다.
- LAMPS: 메모리 사용량 예측을 활용하여 외부 도구 연동 시 효율성을 높인다.
- Parrot: 각 요청에 의미론적 변수(Semantic Variables)로 태그를 지정하여, 특히 에이전트 시나리오에서 요청 간의 종속성 및 공통점을 식별하고 이를 통해 스케줄링을 최적화한다. (Parrot은 초기 접근 방식으로 추가 연구가 필요함)
4.7 Test-Time Reasoning
추론 시점에 적용되는 알고리즘들은 LLM의 추론 능력을 향상시킬 수 있지만, 이는 종종 많은 수의 토큰을 생성함으로써 달성되므로 계산 리소스에 부담을 줄 수 있다.
- Dynasor: 모델의 추론 진행 상황을 동적으로 추적하고, 작업 난이도에 따라 계산 리소스를 조정하며, ‘Certaindex’라는 지표를 도입하여 가망 없는 요청을 사전에 종료한다.
- Damani et al.: 내장된 보상 모델을 사용하여 각 요청에 대한 추가 계산의 한계 이점을 평가하고, 이를 기반으로 다양한 LLM 사용이나 컴퓨팅 예산과 같은 리소스 할당을 최적화한다.
5. Future Works
LLM 추론 서비스 분야의 빠른 발전을 고려하여, 다음과 같은 향후 연구 방향을 제시한다.
- 종속성 제약 조건이 있는 스케줄링 (Scheduling with Dependency Constraints):
- 사용자 요청이 여러 하위 요청으로 구성되고, 이 하위 요청들이 특정 순서대로 모두 완료되어야만 전체 요청이 완료되는 시나리오를 고려한 스케줄링 기법이 필요하다.
- 대규모 멀티모달 모델 서비스 (Large-scale Multimodal Model Serving):
- 현재 대규모 멀티모달 모델은 단일 시스템(monolithic system)으로 배포되고 있으나, 텍스트와 이미지 입력 간의 처리량 불균형과 인코딩 시간 차이 등의 특성을 활용한 효율적인 서비스 최적화 방안 연구가 필요하다.
- 지능형 LLM 추론 서비스 (Intelligent LLM Inference Serving):
- 소규모 LLM을 활용하여 대규모 LLM의 배포, 스케줄링, 스토리지 관리를 최적화하는 방안으로, 작은 LLM이 큰 LLM의 부하 예측이나 요청 분배 등의 지능형 관리 역할을 수행하는 연구가 필요하다.
- 안전 및 개인 정보 보호 (Safety and Privacy):
- 클라우드 기반 LLM 서비스에서 KV 캐시 등 민감 정보의 유출을 방지하고, 데이터 유출 시에도 사용자 대화 내용의 재구성이 불가능하도록 하는 강력한 프라이버시 보호 기술 연구가 필요하다.
6. Conclusion
본 연구는 대규모 언어 모델(LLM) 추론 서비스가 직면한 메모리 및 연산 효율성 문제를 해결하기 위한 최적화 전략들을 다각적으로 소개하고 있다. 인스턴스 수준의 세밀한 기법부터 클러스터 규모의 거시적 접근, 그리고 긴 컨텍스트 처리, RAG, MoE와 같은 추론 시나리오에 이르기까지, LLM 추론 성능을 극대화하기 위한 다양한 기술적 진보를 확인할 수 있었다.
특히, 동적 자원 할당, 지능형 스케줄링, 그리고 하드웨어와 소프트웨어의 유기적인 결합이 향후 인퍼런스 효율성 향상의 핵심임을 인지할 수 있었고, 본 논문을 통해 LLM 인퍼런스 최적화의 현주소를 폭넓게 이해하고, 종속성 기반 스케줄링, 멀티모달 모델 서비스, 그리고 지능형 추론 시스템과 같은 미래 연구 방향에 대한 구체적인 감을 잡을 수 있었다.