[WWDC24 리뷰] Apple Intelligence
Apple은 지난 6월 10일 WWDC24에서 iOS 18, iPadOS 18, 그리고 macOS Sequoia에 탑재될 Apple Intelligence에 대해 발표하였다. 이와 함께 두 가지 언어 모델도 공개하였다.
- 3B 크기의 온디바이스 언어 모델
- Apple 실리콘 서버에서 실행되는 더 큰 서버 기반의 언어 모델
이 모델들은 텍스트 작성 및 다듬기, 알림 우선순위 지정 및 요약, 가족 및 친구와의 대화를 위한 재미있는 이미지 생성, 그리고 앱 간 상호 작용을 간소화하는 인앱 작업 등을 통해 사용자 경험을 향상시키기 위해 파인 튜닝되었다.
OpenELM
Apple은 기본 모델로 어떤 모델을 사용하는지 명확하게 밝히지는 않았지만, 지난 4월 3B 매개변수 버전을 포함한 OpenELM(Open-source Efficient Language Models)이라는 모델을 공개하였다. 따라서 OpenELM이라는 모델에 대해 간략하게 소개하겠다.
OpenELM의 대표적인 특징은 다음과 같다:
- 트랜스포머의 각 레이어에서 파라미터 수를 변화시킴으로써 모델 전체의 파라미터를 효율적으로 분배하는 ‘layer-wise scaling’ 기술을 사용한다.
- 원본 논문에서는 이 기술을 ‘block-wise scaling’이라고 소개하였다.
- 입력에 가까운 레이어에서는 어텐션과 피드 포워드 네트워크의 파라미터 차원을 작게 하고, 출력에 가까워질수록 레이어의 차원을 넓게 할당한다.
OpenELM이 사전 학습에 사용한 아키텍처는 다음과 같다:
- RMSNorm을 사용하여 pre-normalization
- 위치 임베딩 → 회전식 위치 임베딩(RoPE)
- 멀티 헤드 어텐션(MHA) → 그룹화된 쿼리 어텐션(GQA)
- 피드 포워드 네트워크(FFN) → SwiGLU FFN
- scaled dot product 연산에 flash attention
- LLaMA Tokenizer
Flash Attention을 제외하면, OpenELM 모델은 LLaMA2-34B 이상의 모델 및 LLaMA3의 훈련 아키텍처와 동일하였다. instruct tuning에는 rejection sampling 또는 DPO(Direct Preference Optimization)를 사용하였으며, PEFT 기법으로는 LoRA와 DoRA를 활용했지만, 두 기법 간의 성능 차이는 크지 않았다.
벤치마크 상에서는 2배 더 적은 사전 학습 토큰으로 비슷한 크기의 OLMo-1.2B보다 OpenELM-1.1B 모델의 정확도가 2.36% 더 높았다. OpenELM의 주요 의의는 드라마틱한 성능 향상보다는 트랜스포머 레이어를 효율적으로 할당함으로써 더 적은 레이어로도 성능을 유지하거나 약간 향상시키는 것으로, 이는 온디바이스 모델의 파라미터 크기를 줄이기 위함으로 보인다.
따라서, Apple Device에 사용되는 기본 모델은 OpenELM-3B에서 파생된 모델이라고 추정된다. 이는 공개된 OpenELM의 어휘 크기가 32K인 반면, 온디바이스 모델은 49K를 사용하고, 기존 OpenELM은 안전성을 위한 조정을 거치지 않았기 때문이다.
지금부터는 블로그에서 소개한 Apple 기본 모델에 대한 모델링 개요를 따라 설명하겠다.
Data & Preprocessing
데이터 수집은 웹 크롤러인 AppleBot이 수집한 공개 데이터를 사용하였다. 또한, 특정 기능을 향상시키기 위해 선택된 데이터와 라이센스 데이터를 활용하였다. Apple은 라이센스 데이터를 위해 Shutterstock과 훈련용 이미지 데이터 계약을 약 2,500만 ~ 5,000만 달러에 체결하였다. 이외에도 다른 데이터 소스가 더 있을 것으로 추정된다.
Apple은 인터넷에 공개된 개인 식별 정보를 제거하고, 욕설 및 기타 품질이 낮은 콘텐츠를 필터링하였다. 또한, 데이터 추출, 중복 제거, 모델 기반 분류기를 적용하여 고품질 문서를 식별하였다.
Pre-Training
기본 모델은 Apple의 AXLearn 프레임워크에서 학습되었으며, OpenELM의 아키텍처를 따른 것으로 추정된다.
Post-Training
Apple은 기본 모델을 훈련 후 두 가지 새로운 알고리즘을 개발하고 적용하였다.
- a rejection sampling fine-tuning algorithm with teacher committee
- rejection sampling은 다수의 response를 생성하고 그중에서 reward score가 가장 높은 response를 채택하여 모델을 업데이트하는 과정으로 LLaMA2에서 처음 등장하였다.
- teacher committee는 더 크고 좋은 성능의 모델을 참조하여 생성된 학습 예제의 품질을 평가하는 방법이다. 보통 GPT-4 및 Claude 3와 같은 모델을 teacher로 사용하지만 Apple이 예제 평가에 어떤 모델을 사용했는지는 명확하지 않다.
- a reinforcement learning from human feedback (RLHF) algorithm with mirror descent policy optimization and a leave-one-out advantage estimator.
- RLHF는 인간이 주석을 단 데이터를 사용하여 사용자 선호도를 모델링하고 언어 모델이 지시를 더 잘 따르도록 훈련하는 방법이다.
- Apple은 인간이 주석을 단 데이터와 합성 데이터를 모두 통합한 하이브리드 데이터 전략을 적용하였다.
위 두 알고리즘이 모델의 instruction-following quality를 크게 향상시켰다고 한다.
Optimization
추론 속도와 효율성을 위해 온디바이스 및 프라이빗 클라우드에서 최적화하기 위한 다양한 혁신적인 기법들을 사용하였다.
- GQA
- low-bit palletization
- activation and embedding quantization
- LoRA
GQA
온디바이스와 서버 모델은 모두 그룹화된 쿼리 어텐션(GQA)을 사용한다.
GQA는 MHA와 MQA의 중간 개념이다. MQA처럼 여러 개의 KV 헤드를 1개로 줄이는 대신, GQA는 이를 적절한 G개의 그룹으로 줄인다. G가 1이면 MQA가 되고, H이면 MHA가 되므로 GQA는 MHA와 MQA를 포함하는 일반화된 형태라고 할 수 있다.
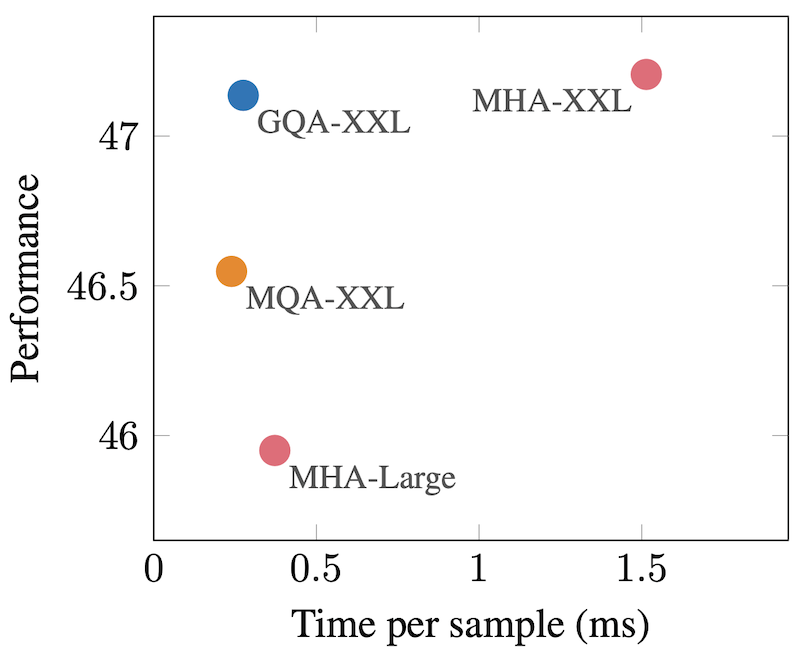
아래 그림은 GQA가 MQA와 비슷한 속도를 유지하면서도 MHA와 비슷한 성능을 보여주는 뛰어난 방법임을 나타낸다. GQA에서는 그룹 크기를 H의 제곱근 정도로 설정하는 것이 일반적이다.
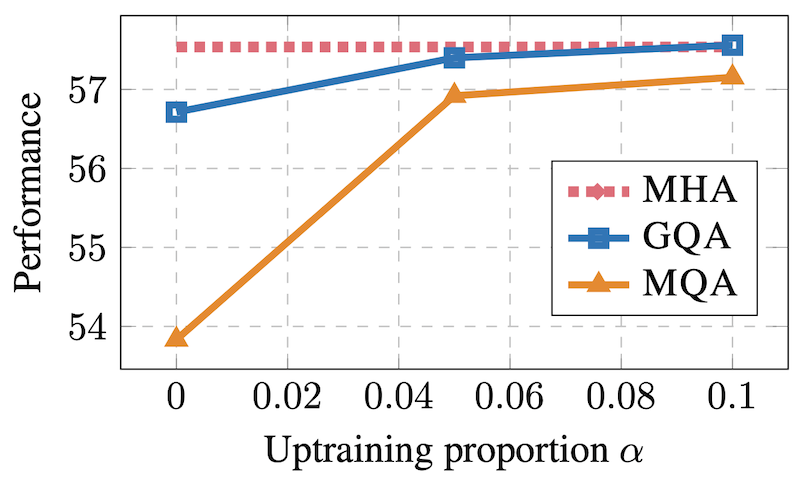
또한, GQA는 pre-trained된 모델에 post-training으로 적용할 수 있다.
아래 그래프는 pre-trained된 모델에 추가로 𝛼%만큼 GQA로 학습시켰을 때의 성능을 보여준다. 𝛼가 높을수록 MHA와 성능이 비슷하며, 0일 때에도 성능 저하가 크지 않음을 알 수 있다.
low-bit palletization
온디바이스 추론에 있어서는 메모리, 전력 및 성능 요구 사항을 달성하기 위한 중요한 최적화 기법인 low-bit palletization을 사용한다.
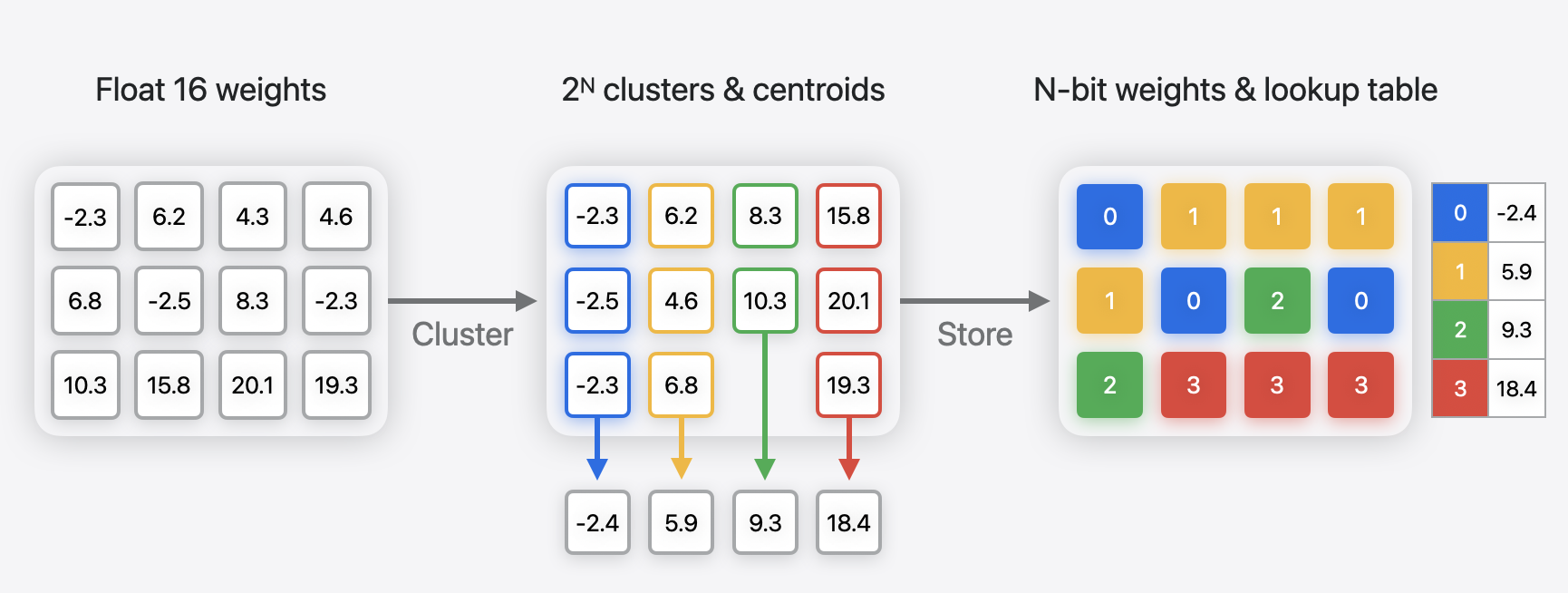
팔레트화는 가중치 클러스터링이라고도 하며, 모델의 float 가중치를 클러스터링하고 중심값의 룩업 테이블(LUT)을 생성한 다음 원래 가중치 값을 LUT의 항목을 가리키는 인덱스와 함께 저장하여 모델을 압축한다.
압축된 N-bit 가중치는 직접 계산에 사용할 수 없으며, 테이블에 대한 인덱스로만 사용되기 때문에 추론 시에는 팔레트에 저장된 가중치를 압축 해제해야 한다.
압축 해제 작업이 많아 다소 느릴 수 있지만, 일반적으로 FP16 모드에서 전체 가중치를 로드하는 것보다 더 효율적이다. 압축되지 않은 데이터를 전송하는 것보다 더 적은 양의 메모리를 전송하기 때문에 더 빠르게 동작한다.
Apple은 2비트 및 4비트 혼합 구성 전략(averaging 3.5 bits-per-weight)을 사용하였다.
activation and embedding quantization
활성화 및 임베딩에 양자화를 적용하였으며, 양자화 알고리즘은 CoreML 문서에 따르면 GPTQ 및 QAT로 추정된다.
LLM in a flash
Apple의 모델은 M1 이상 칩이 탑재된 MacBook과 A17 Pro 칩이 탑재된 iPhone 15 Pro 및 Pro Max에서만 실행된다. 이는 LLM in a flash 등 애플 실리콘 칩에 적합한 일부 최적화 기술을 사용하고 있음을 시사한다.
일반적으로 7B 모델을 로드하려면 14GB의 메모리가 필요하지만, 이는 대부분의 엣지 디바이스의 용량을 초과한다. 이를 해결하기 위한 일반적인 방법은 4비트 또는 8비트 정수로 양자화하는 것이다. 그러나 양자화에는 모델 수정이나 전체 모델의 재학습이 필요한 경우가 많습니다.
LLM in a flash의 주요 목적은 플래시 메모리를 사용하여 모델 매개변수를 저장함으로써 제한된 DRAM 용량을 가진 장치에서 LLM을 실행하는 과제를 해결하는 것이다. 플래시 메모리에서 데이터 전송과 읽기 처리량을 최적화하여 사용 가능한 DRAM 용량을 초과하는 LLM을 효율적으로 추론할 수 있도록 한다.
다음은 플래시 메모리에서 DRAM으로 모델을 로드하는 과정을 간소화하도록 설계된 일련의 최적화 기술을 소개한다:
- Leveraging model sparsity
- Sliding windows
- Bundling Columns and Rows
Leveraging model sparsity
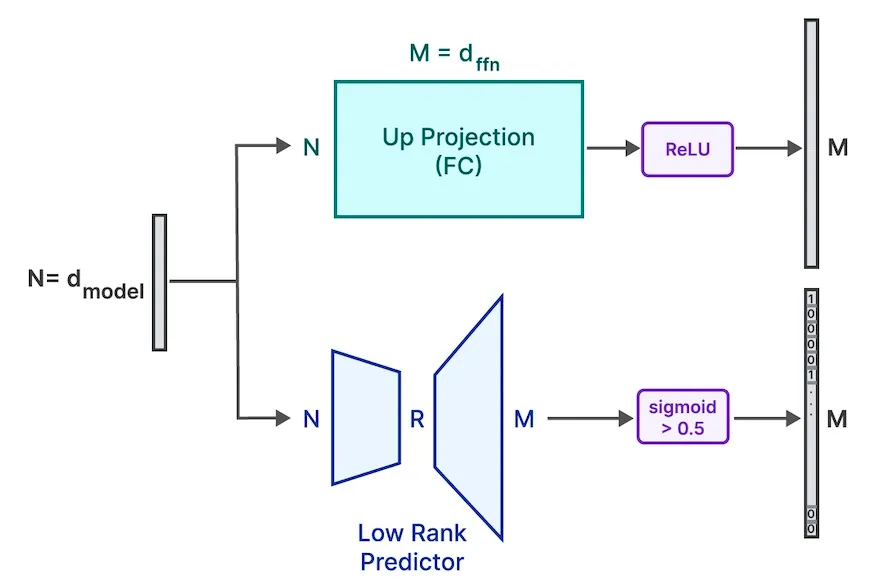
언어 모델은 어텐션 메커니즘와 피드 포워드 네트워크라는 두 가지 중요한 요소로 구성된 트랜스포머 블록에 의존한다. 연구에 따르면, LLM의 FFN은 희소성이 높아 활성화 후 값이 0이 되거나 거의 0에 가까워져 추론과 관련이 없게 되는 경우가 많다.
Apple의 연구진은 추론 중에 희소하지 않은 요소만 찾아 로드하면 메모리 비용을 획기적으로 줄일 수 있다고 밝혔다. 그들의 전략은 비교적 작은 어텐션 레이어를 완전히 로드하는 동시에 FFN의 희소하지 않은 세그먼트만 DRAM에 선택적으로 로드하는 것이다.
이를 달성하기 위해 FFN의 어느 부분이 비희소할지를 결정하고 로드해야 하는 데이터 양을 줄이는 “Low Rank Predictor” 네트워크를 사용한다. 그런 다음, 이 예측기가 식별한 활성 뉴런을 메모리로 전송한다.
Sliding windows
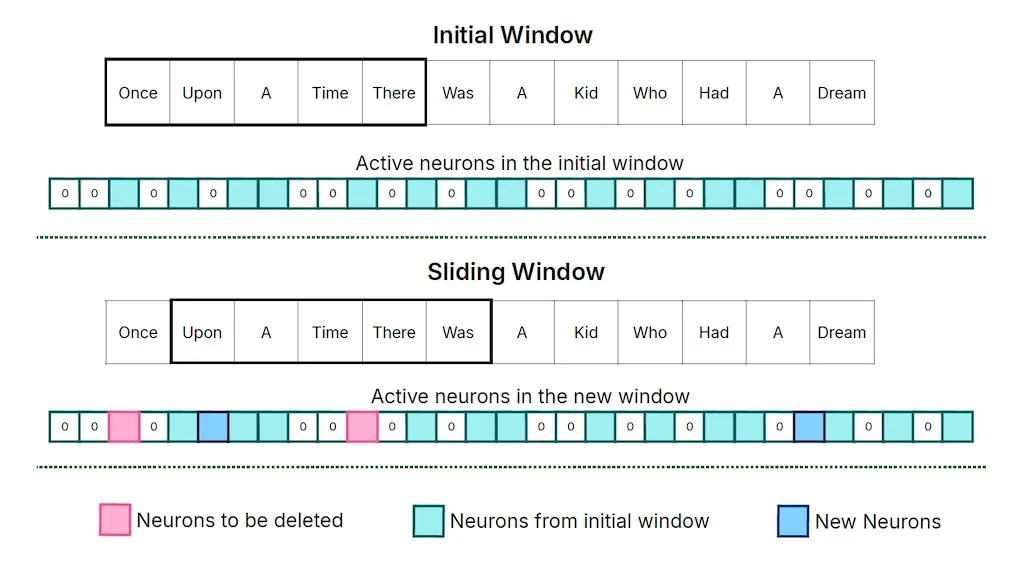
Apple의 연구원들은 또한 모델 추론 중에 뉴런의 로딩과 언로딩을 관리하기 위해 “Sliding Window Technique”을 고안하였다. 이 방법은 메모리에 최근 입력 토큰의 하위 집합에서 필요한 것으로 예측된 가중치 행만 DRAM 캐시에 보관하고, 새 토큰이 들어오면 이전 토큰의 공간을 해제한다.
이 전략을 사용하면 새 토큰마다 최소한의 뉴런만 스왑하면 되므로 플래시 메모리에서 RAM으로의 데이터 전송이 간소화된다. 또한, 더 이상 슬라이딩 윈도우 내에 있지 않은 토큰에 필요한 캐시된 가중치에 할당된 메모리 리소스를 확보할 수 있어 효율적인 메모리 활용이 가능하다.
슬라이딩 윈도우의 크기는 모델을 실행하는 장치의 메모리 크기에 따라 조정할 수 있다.
Bundling Columns and Rows
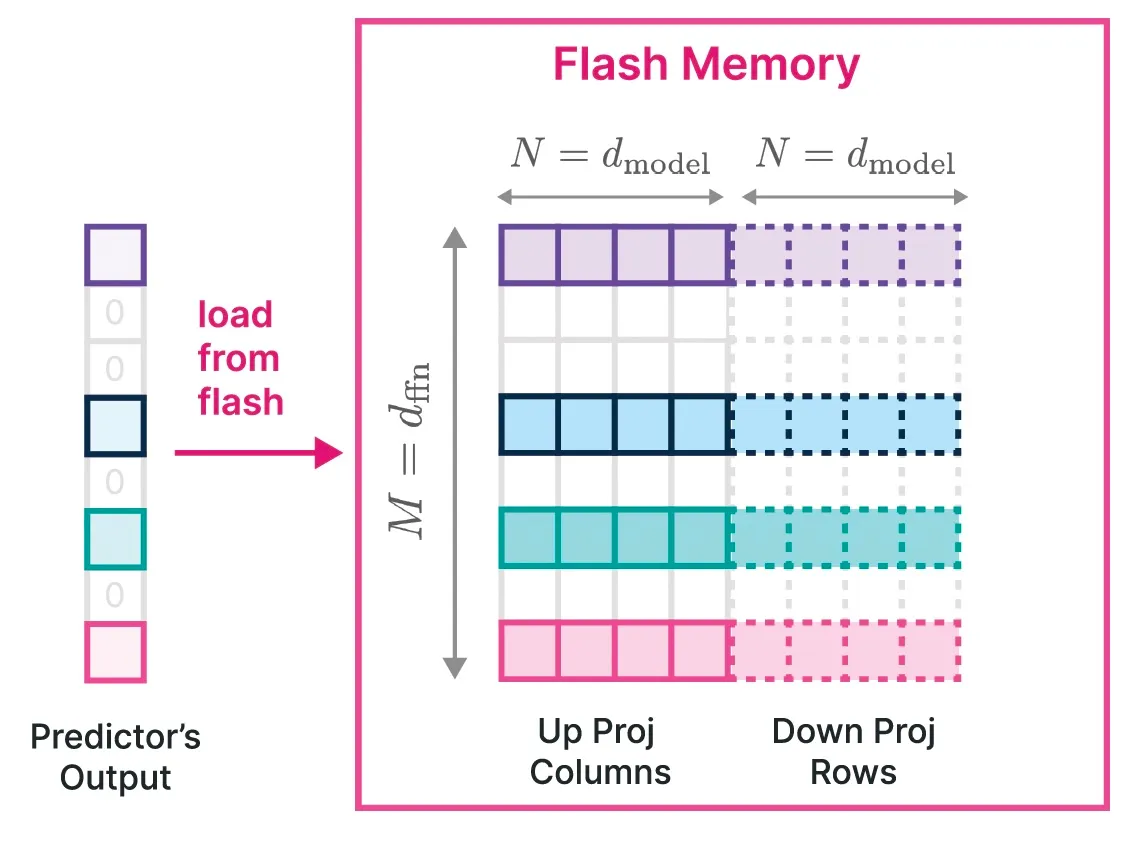
플래시 메모리에서 데이터 처리량을 늘리기 위해서는 더 큰 청크로 데이터를 읽는 것이 중요하며, 여기서는 청크 크기를 늘리는 데 사용한 전략에 대해 설명한다.
OPT 및 Falcon 모델의 경우, upward projection에서 𝑖번째 열과 downward projection에서 𝑖번째 행의 사용은 𝑖번째 중간 뉴런의 활성화와 일치한다. 이러한 해당 열과 행을 플래시 메모리에 함께 저장함으로써, 데이터를 더 큰 청크로 통합하여 읽을 수 있다.
이 전략의 핵심은 행렬의 특정 부분, 즉 row와 column을 함께 번들로 묶어 처리함으로써 데이터를 효율적으로 로드하고 관리하는 것이다. 연구진들은 공동 활성화된 뉴런을 함께 저장하는 것의 이점을 조사하였다. 비록 연구 결과가 기대에 미치지 못했지만, 뉴런을 효과적으로 묶는 방법과 이를 효율적인 추론에 활용하는 방법에 대한 흥미로운 미래 연구 방향을 제시하였다.
Faster LLMs on low-memory devices
플래시 메모리로 사용되는 1TB SSD가 있는 M1 Max에서 각 추론에 대해 플래시 메모리에서 RAM으로 모델을 naive하게 로드하면 토큰당 2.1초의 지연 시간이 발생하게 된다. 하지만 위에서 소개한 sparsity prediction, windowing, intelligent storage와 같은 새로운 기술을 구현함으로써 이 지연 시간을 약 200밀리초로 단축하였다. GPU가 장착된 시스템에서 개선 효과는 더욱 두드러졌다.
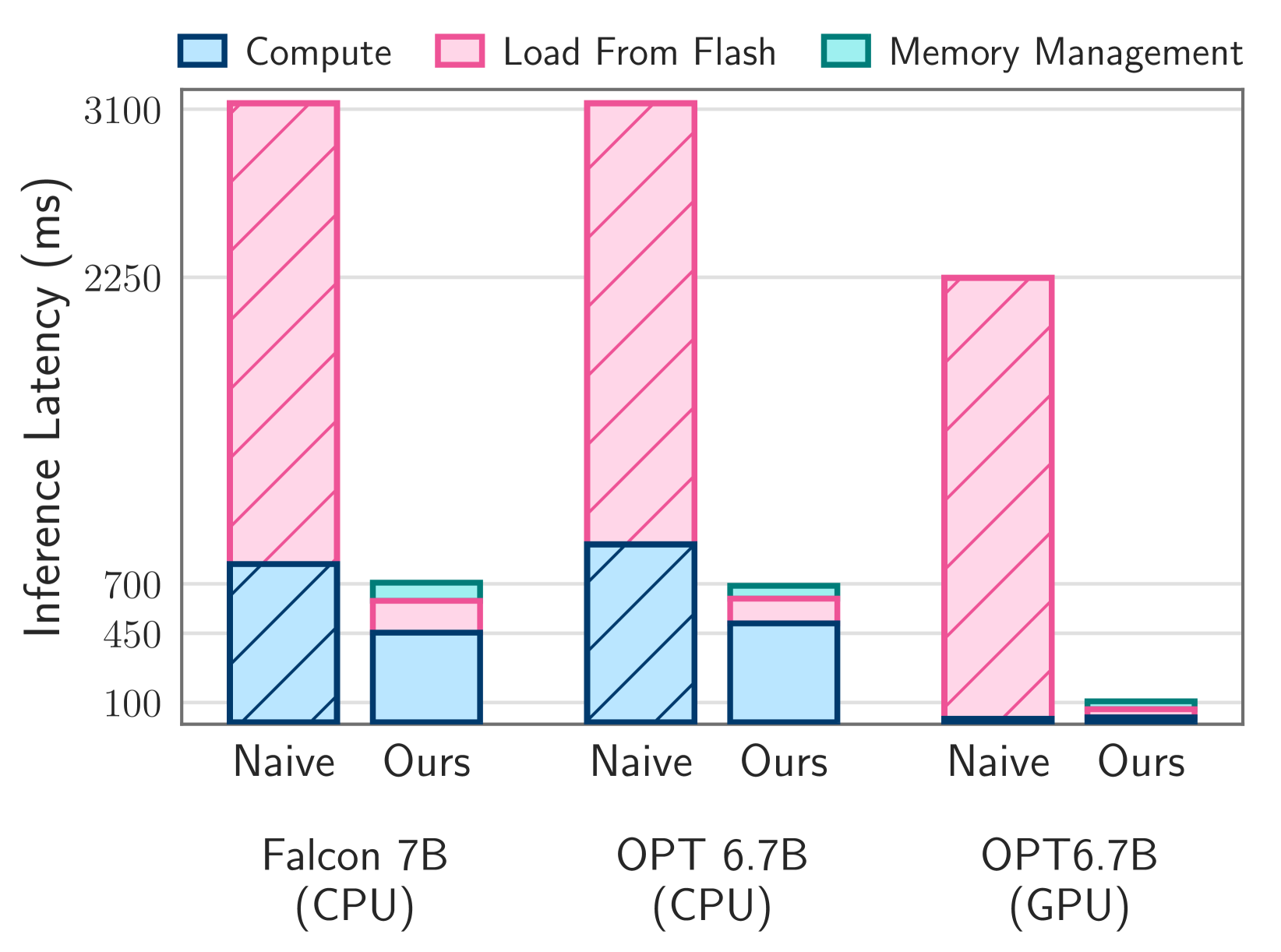
연구진들은 “우리는 사용 가능한 DRAM의 최대 2배 크기까지 LLM을 실행할 수 있는 능력을 입증하여 CPU에서는 기존 로딩 방식에 비해 4~5배, GPU에서는 20~25배의 추론 속도 가속화를 달성했다.”라고 설명한다.
Model Adaptation
LoRA는 파인튜닝 과정에서 효율성을 높이기 위해 개발된 기법이다.
특정 레이어의 파라미터를 저차원(low-rank)으로 분해하여 일부만 업데이트함으로써 메모리와 계산량을 크게 줄이며, 적은 수의 파라미터만 저장하고 업데이트할 수 있어 대규모 모델의 파인튜닝에서 효율적이다. 이는 다양한 응용 분야에 쉽게 적용할 수 있으며, 원래 모델의 성능을 유지하면서도 특정 작업에 맞게 조정할 수 있다.
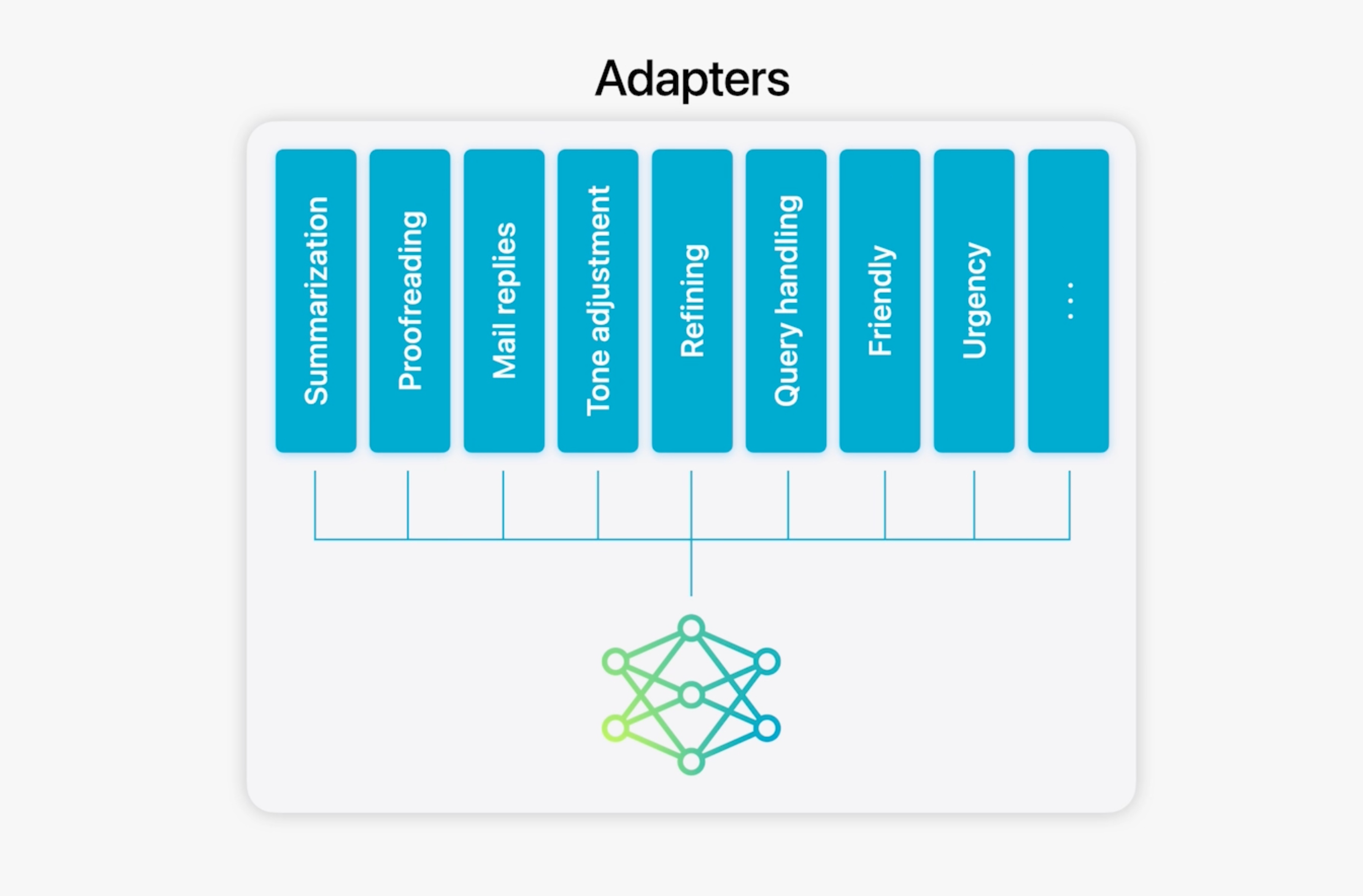
Apple 온디바이스 모델은 rank 16의 LoRA 어댑터를 사용하여 추론 시 기본 모델과 결합한다. 각 어댑터는 100MB 미만으로 요약, 교정, 이메일 회신 등과 같은 다양한 작업에 여러 LoRA 어댑터를 저장하고 사용할 수 있다. 또한, 어댑터의 훈련을 용이하게 하기 위해 기본 모델이나 훈련 데이터가 업데이트될 때 어댑터를 빠르게 재훈련, 테스트, 배포할 수 있는 효율적인 인프라를 구축하였다.
Performance and Evaluation
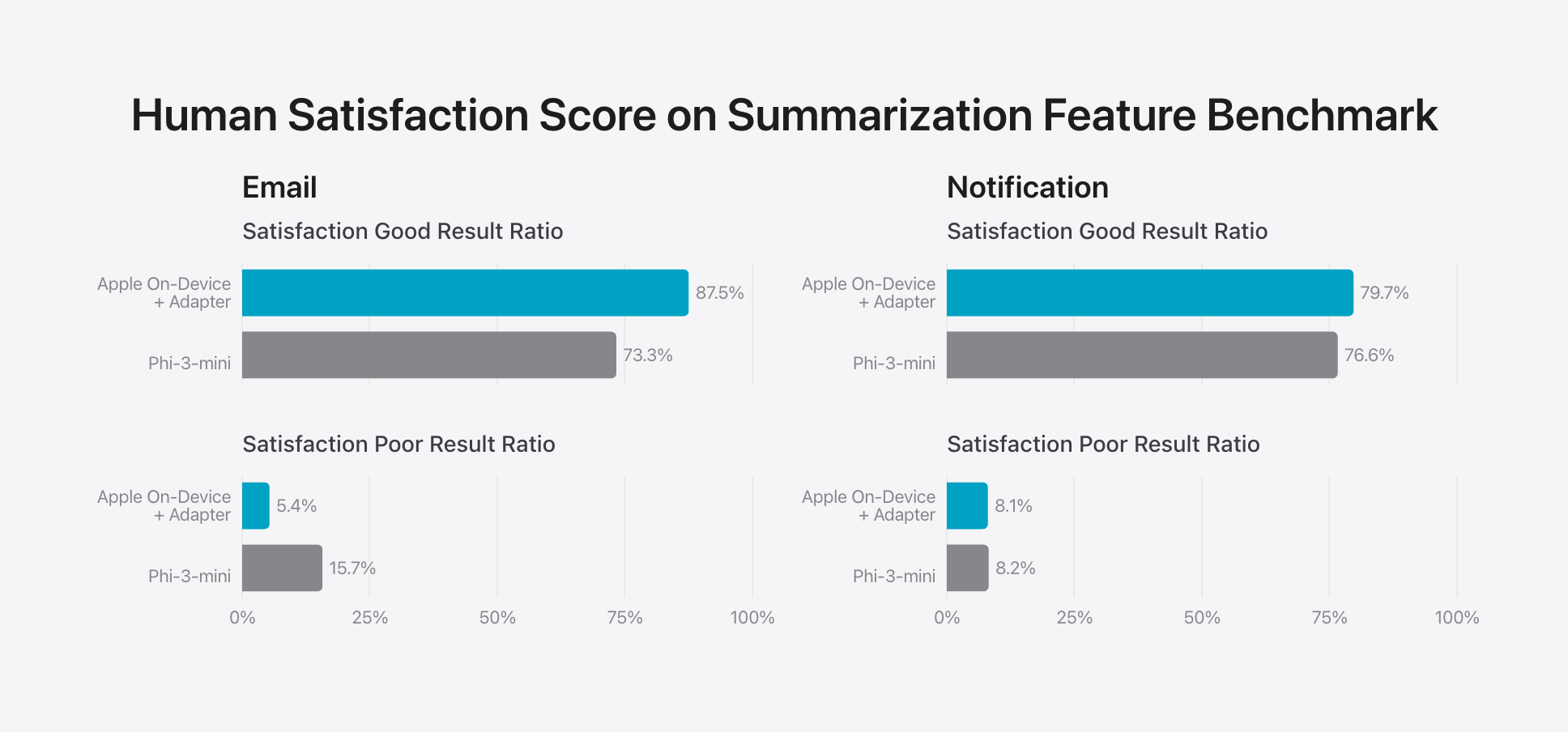
제품별 요약 기능을 평가하기 위해 각 사용 사례에서 신중하게 샘플링한 750개의 응답 세트를 사용하여 인간 만족도 점수를 평가하였다. Apple 온디바이스 모델 + 어댑터를 phi-3-mini 기본 모델과 비교했을 때, Apple의 모델이 더 나은 요약을 생성하는 것을 확인할 수 있다. 그러나 공정한 비교는 Apple 온디바이스 모델 + 어댑터와 phi-3-mini + 어댑터 간의 비교였을 텐데, Apple은 그렇게 하지 않았다.
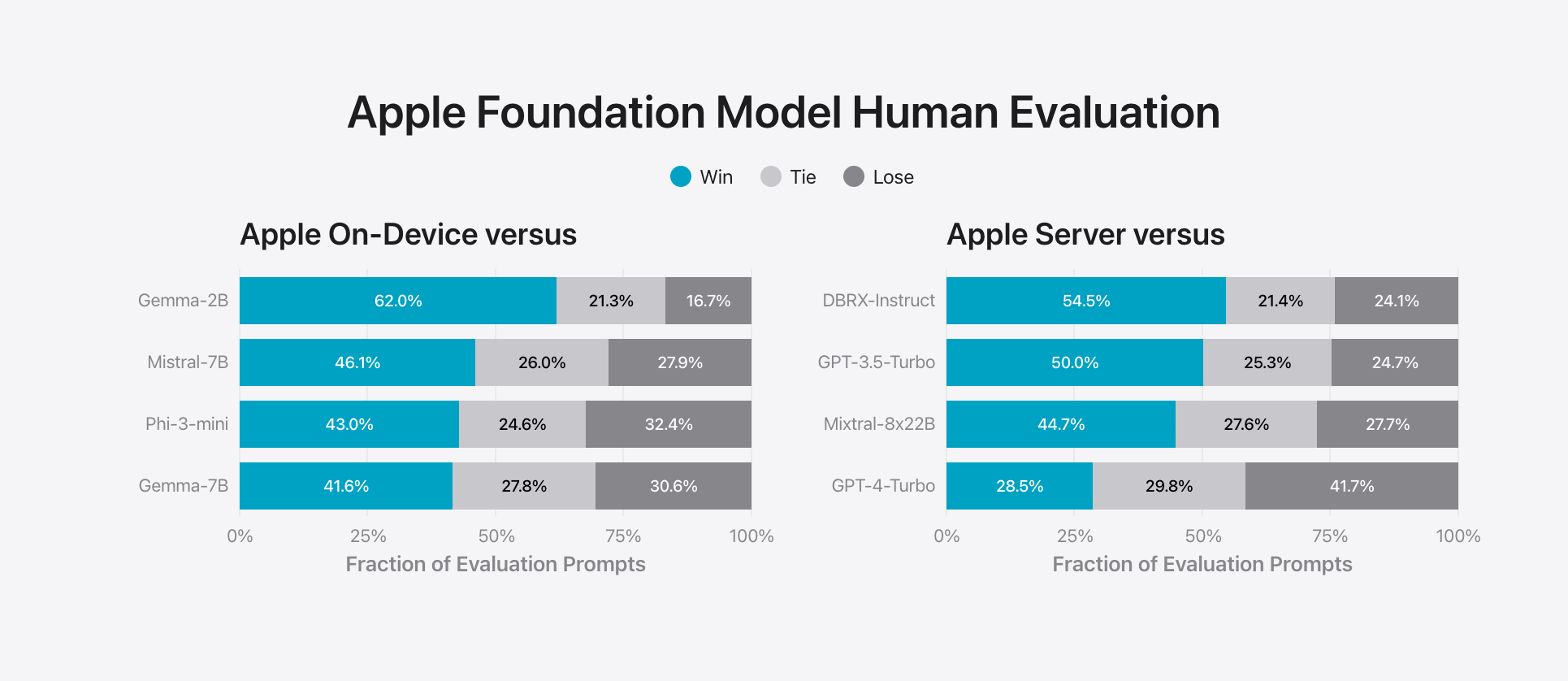
온디바이스 및 서버 기반 모델의 일반적인 기능을 평가하였다. 일반 모델 기능을 테스트하기 위해 난이도에 따라 다양한 브레인스토밍, 분류, 비공개 질문 답변, 코딩, 추출, 수학적 추론, 공개 질문 답변, 재작성, 안전, 요약 및 쓰기 등의 포괄적인 평가 세트를 활용하였다. Apple의 서버 모델은 MoE(Mixture of Experts) 모델들과 비교했으며, 이는 서버 모델 또한 MoE로 구현되었을 가능성이 높다.
Apple의 모델은 대부분의 비슷한 경쟁 모델보다 인간 평가자들에게 더 선호된다는 결과를 얻었다.
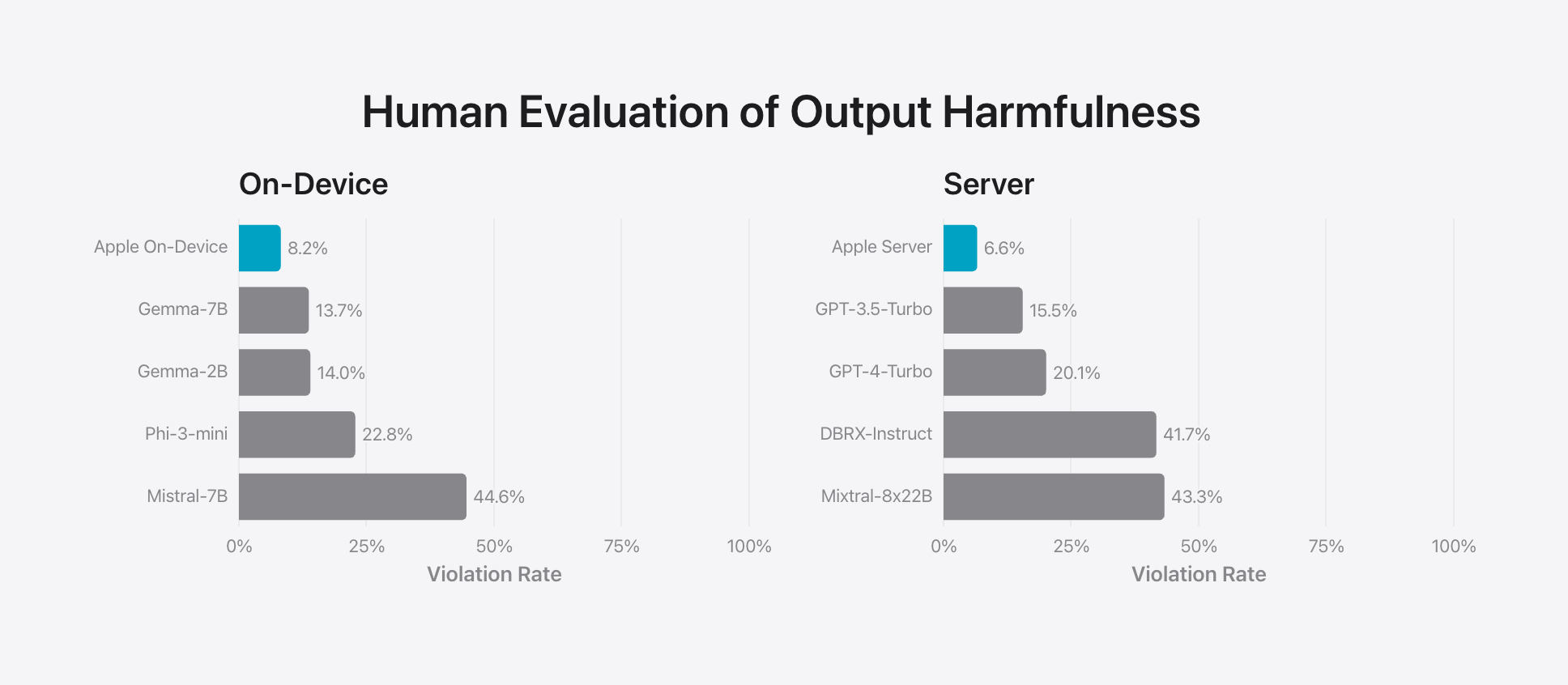
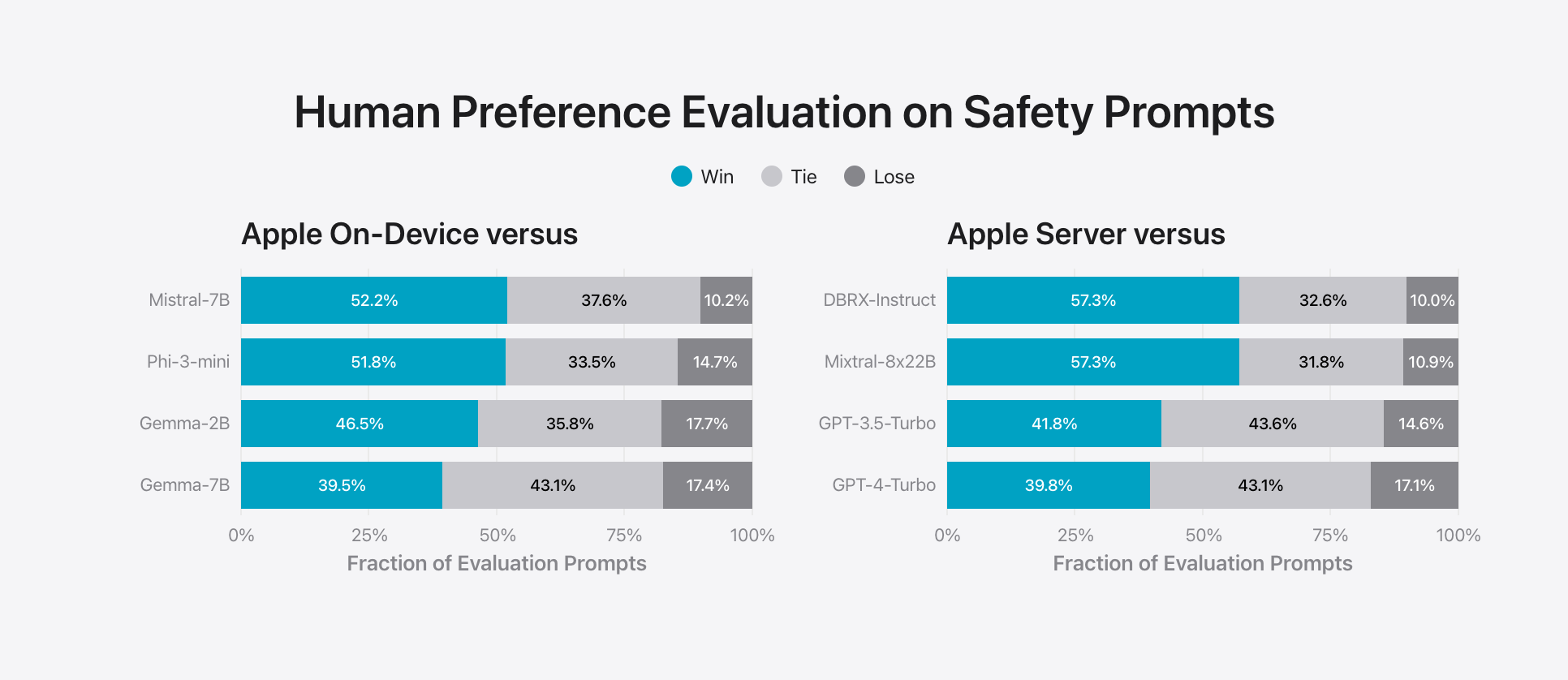
“답변 유해성에 대한 인간의 평가”와 “안전 프롬프트에 대한 인간의 선호도 평가”는 Apple이 모델에서 생성하는 콘텐츠 종류에 대해 매우 우려하고 있음을 보여준다. 온디바이스 및 서버 모델 모두 적대적 프롬프트에 직면했을 때 오픈 소스 및 상용 모델보다 낮은 위반률을 달성하였다. 반면, 미스트랄-7B는 다른 경쟁사들과 달리 유해성 감소에 대해 명시적으로 훈련되지 않았기 때문에 그 결과가 좋지 않다.
Conclusion
지금까지 WWDC24에서 공개한 Apple Intelligence의 온디바이스 및 서버 모델의 주요한 특징 및 전반적인 성능에 대해서 살펴보았다. 3B 규모의 On-Device 모델은 작은 모델을 적절한 최적화 기술, 데이터 및 하드웨어와 결합하면 얼마나 멀리까지 도달할 수 있는지 그 가능성을 보여주었으며, 서버 모델 또한 오픈소스 및 상용 모델들 대비 더 나은 성능을 보였다.
기술 데이터 공개가 완전하지는 않았지만, Apple 치고는 꽤 괜찮은 수준이었다. Apple은 정확도와 최적의 사용자 경험 사이에서 균형을 맞추기 위해 많은 노력을 기울였으며, 기기 내 AI를 최대한 활용하고 클라우드에서 개인 프라이버시를 보장하기 위한 노력도 엿볼 수 있었다.
올가을, iOS 18이 하루라도 빨리 출시되어 직접 활용해보기를 기대한다.
Reference
- https://machinelearning.apple.com/research/introducing-apple-foundation-models
- OpenELM: An Efficient Language Model Family with Open Training and Inference Framework,Mehta et al. arXiv 2024
- DeLighT: Deep and Light-weight Transformer, Mehta et al., arXiv 2021
- https://devocean.sk.com/blog/techBoardDetail.do?ID=165192
- https://apple.github.io/coremltools/docs-guides/source/opt-quantization-algos.html
- https://bdtechtalks.com/2023/12/27/apple-llm-flash-research/
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory, Alizadeh et al.,arXiv 2024
- LoRA: Low-Rank Adaptation of Large Language Models, Hu et al., arXiv 2021