[리뷰] Training Compute-Optimal Large Language Models
본 논문은 2022년 3월에 발표되었다. 본 논문의 주요 목표는 주어진 컴퓨팅 예산에서 언어 모델을 훈련하기 위한 최적의 모델 크기와 토큰 수를 조사하는 것이다.
그동안 Scaling Laws에 따라 모델의 매개변수 수와 성능 사이에 법칙 관계가 있음을 발견하고 점점 더 큰 규모의 모델을 훈련해왔다. 하지만 저자는 175B GPT-3, 280B Gopher 및 530B Megatron과 같은 현재의 LLM이 underfitting 되었다고 언급하며, 학습 토큰 수와 모델 크기를 동일하게 조정해야 한다고 주장한다.
70M에서 16B 이상의 파라미터를 가진 400개 이상의 언어 모델을 5B에서 500B의 토큰으로 훈련한 결과, 컴퓨팅 최적화 훈련을 위해서는 모델 크기와 학습 토큰 수를 동일하게 확장해야 한다는 것을 발견했다. 즉, 모델 크기가 두 배가 될 때마다 학습 토큰 수도 두 배가 되어야 한다. 이를 검증하기 위해, 280B Gopher와 동일한 컴퓨팅 예산을 사용하면서도 70B 매개변수와 4배 더 많은 훈련 데이터를 포함하는 Chinchilla라는 새로운 LLM을 훈련하였다.
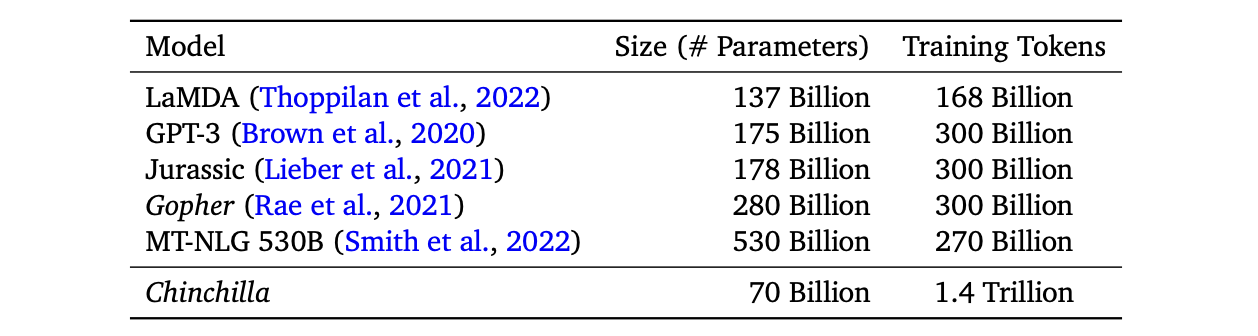
Chinchilla는 다양한 다운스트림 태스크 평가에서 Gopher(280B), GPT-3(175B), Jurassic-1(178B), 및 Megatron(530B)보다 일관되고 유의미한 성능을 보였다.
이 연구의 주요 질문은 “고정된 FLOPs 예산이 주어졌을 때, 모델 크기와 학습 토큰 수를 어떻게 조정해야 할까?”이다. 이를 위해 세 가지 접근 방식을 시도했는데, 먼저 컴퓨팅과 모델 크기 사이의 거듭제곱 관계를 가정하였다.
Estimating the optimal parameter/training tokens allocation
Approach 1: Fix model sizes and vary number of training tokens
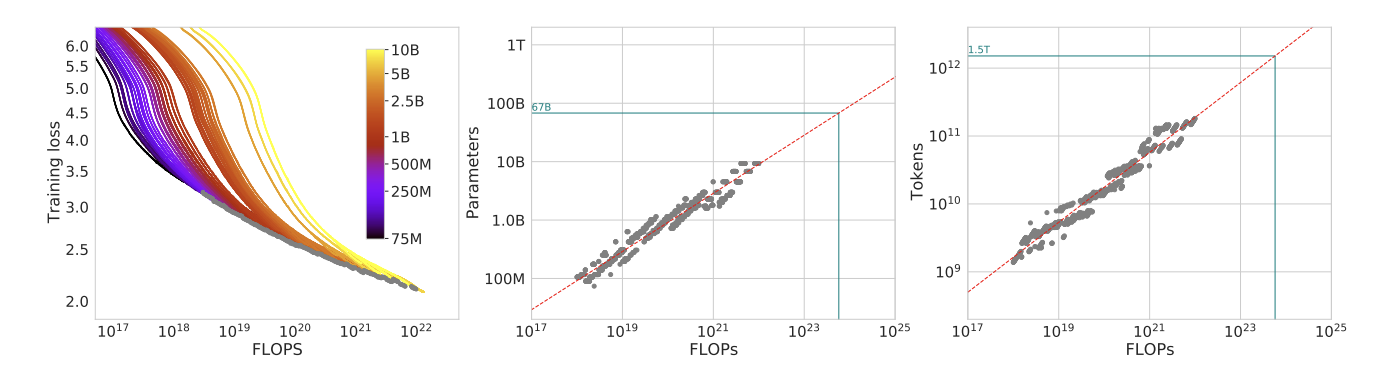
첫 번째 접근 방식에서는 고정된 모델 크기(75M, 250M, 500M, 1B, 2.5B, 5B, 10B)에 대해 고정된 FLOPs로 학습 토큰 수를 변경하였다. 거듭제곱 법칙(\(N_{opt} \propto C^{a}\) 및 \(D_{opt} \propto C^b\))을 사용하여 Gopher의 컴퓨팅 예산(\(5.76 \times 10^{23}\))에 대한 최적의 모델 크기가 67B이며, 이에 대응하는 학습 토큰 수는 1.5T라는 것을 알아냈다.
Approach 2: IsoFLOP profiles
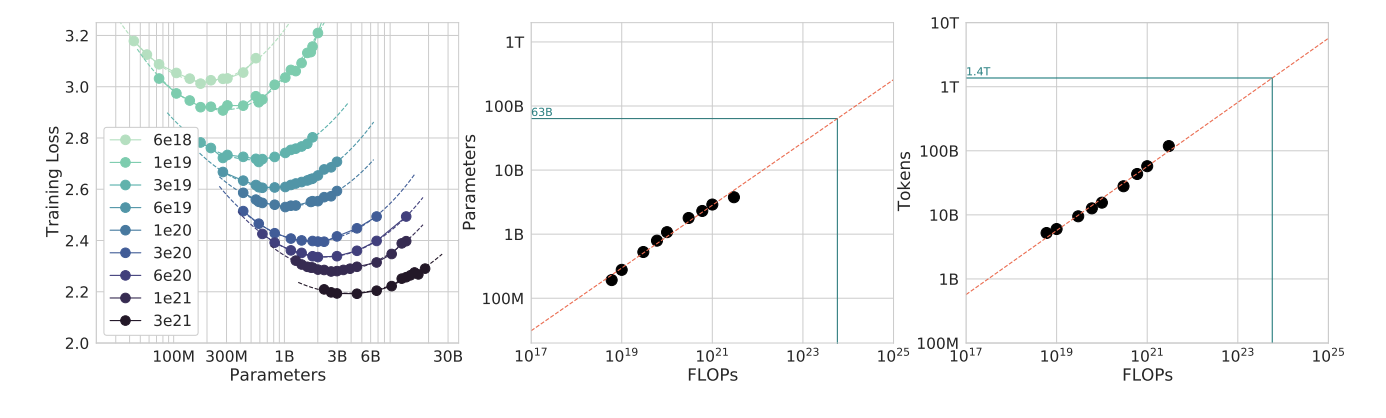
두 번째 접근 방식에서는 9개의 서로 다른 학습 FLOP (\(6 \times 10^{18}\) 에서 \(3 \times 10^{21}\) FLOPs 범위)으로 구성된 고정된 세트에 대해 모델 크기를 변경하고 각 지점에 대한 최종 학습 손실을 고려하였다. 이를 통해 “주어진 FLOP 예산에 대해 최적의 파라미터 수는 얼마인가?”에 대한 질문에 답하고자 하였다.
각 IsoFLOPs 곡선에 포물선을 맞춰 최소 손실이 달성되는 모델 크기를 직접 추정하였다. 그런 다음, 이전 접근 방식과 마찬가지로 FLOP과 최적의 모델 크기 및 학습 토큰 수 사이에 거듭제곱 법칙(\(N_{opt} \propto C^{a}\) 및 \(D_{opt} \propto C^b\))을 적용하였다.
이 접근 방식은 Gopher의 컴퓨팅 예산에 대한 최적의 모델 크기가 63B이고 학습토큰이 1.4T가 되어야 함을 시사한다.
Approach 3: Fitting a parametric loss function
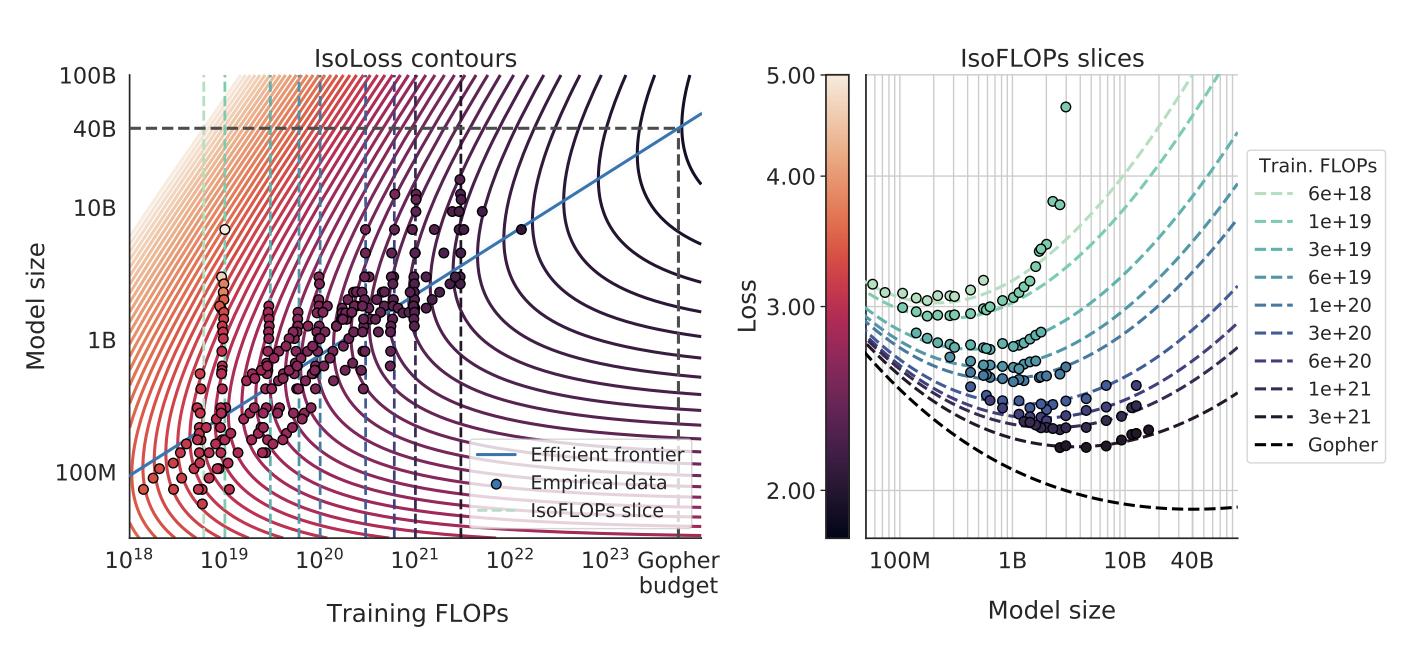
세 번째 접근 방식에서는 위의 두 가지 접근 방식의 결과를 결합하여 모델 매개변수와 토큰 수의 매개변수 함수로 표현하고자 하였다. 이를 위해 함수형을 제안하고 Huber 손실을 최소화하여 Gopher Flop 예산에 대한 최적의 모델 크기를 40B 매개변수로 추정하였다.
Chinchilla
섹션 3에 따르면 Gopher의 컴퓨팅 예산에 대한 최적의 모델 크기는 40B에서 70B 사이이다. 이를 검증하기 위해 1.4T 토큰의 데이터셋으로 70B 크기의 모델을 훈련하고 Chinchilla라고 명명하였다. 이후 이 모델을 Gopher 및 다른 LLM과 비교하여 성능을 평가하였다.
Chinchilla를 학습시키는 데 사용되는 전체 하이퍼파라미터는 다음 표와 같다.

Results

Chinchilla는 위의 Language Modeling 및 downstream task에서 평가하였다.
Language Modeling
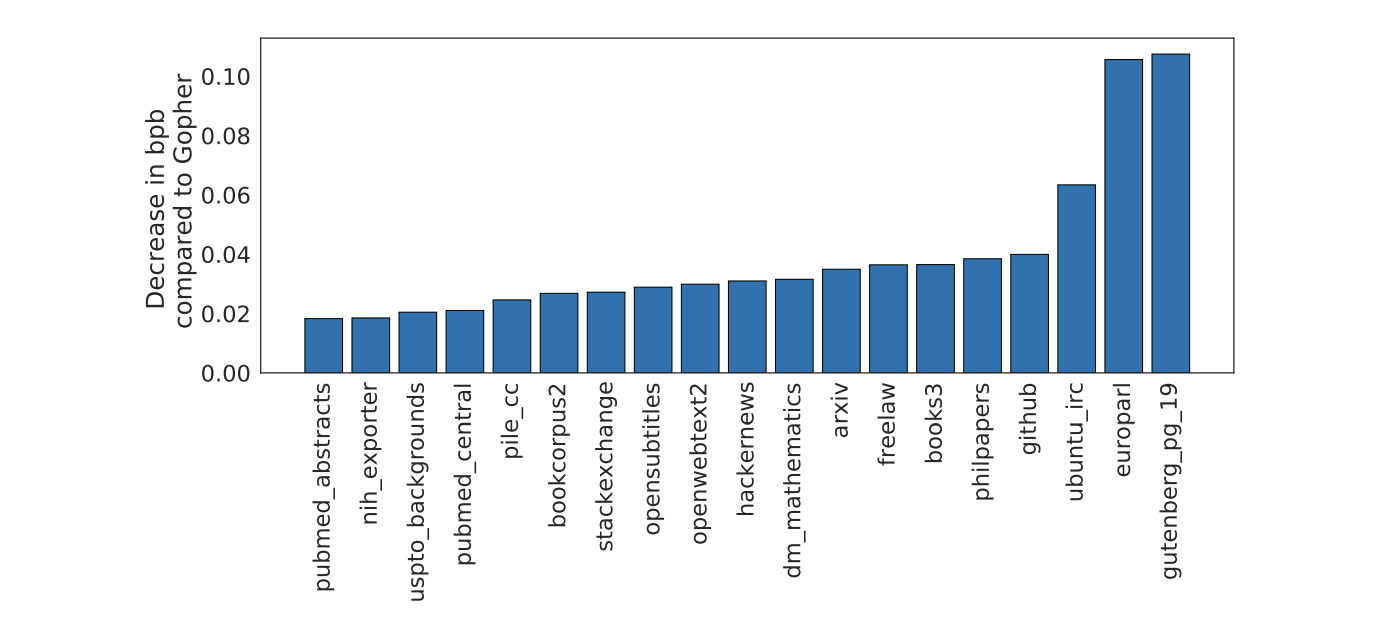
그림 5는 The Pile이라는 모든 평가 데이터셋에 대한 결과를 Gopher와 비교한 결과이다. Chinchilla는 Gopher를 크게 능가하는 성능을 보여주고 있으며, Jurassic-1 (178B)과 비교했을 때도 두 개의 태스크(dm_mathematics 및 ubuntu_irc)를 제외한 모든 subset에서 Chinchilla가 우세한 것을 확인할 수 있다.
MMLU

MMLU는 모델의 멀티태스크 정확도를 측정하는 데이터셋으로, 인문학, 초등 수학, 역사, 컴퓨터 과학, 법률 등 57개의 주제를 포함하고 있다. 이 벤치마크에서 Chinchilla는 평균 정확도가 67.6%로, 훨씬 작은 크기에도 불구하고 Gopher를 크게 앞섰다. Gopher보다 7.6% 향상된 성능을 보였으며, 2023년 6월 전문가들이 예측한 정확도 63.4%를 능가하는 정확도를 기록하였다.
Conclusion
최근 대규모 언어 모델 학습의 추세는 학습 토큰 수를 늘리지 않고 모델 크기를 늘리는 것이었다. 그러나 400회 이상의 훈련 결과를 바탕으로 세 가지 접근 방식을 제안하였고, 이를 통해 Gopher의 크기가 상당히 과대하다는 것을 확인하였다. 더 많은 데이터로 훈련된 더 작은 모델인 Chinchilla가 Gopher는 물론 더 큰 규모의 모델보다 성능이 뛰어난 것을 확인할 수 있었다.
따라서 모델 크기를 계속해서 늘리는 것보다 데이터셋의 확장에 더 집중해야 하며, 데이터셋의 품질에 중점을 두고 책임감 있게 수집해야 한다. 또한 대규모 모델을 훈련하는 데는 많은 비용이 들기 때문에, 최적의 모델 크기를 계산하고 학습 단계를 미리 선택하는 것이 중요한데, Chinchilla Scaling Law는 대규모 언어 모델의 성능과 기능 향상을 위한 컴퓨팅 최적화 접근 방식을 제공한다.