[리뷰] Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Munkhdalai, T., Faruqui, M., & Gopal, S. “Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention” arXiv preprint arXiv:2404.07143, 2024. [paper]
Google DeepMind 팀은 2024년 4월, LLM의 컨텍스트 길이를 무한히 확장할 수 있는 Infini-attention 기술을 발표하였다. 이를 바탕으로 Google은 Gemini 1.5를 100만 토큰의 컨텍스트 윈도우로 출시했으며, 이는 Gemini 1.0(32K)보다 약 32배 증가한 수치이다. 얼마 지나지 않아 Gemini 1.5 Flash를 200만 토큰의 컨텍스트 윈도우로 선보였다. 이러한 급격한 발전은 “무한한 컨텍스트(infinite context)“를 향한 새로운 지평을 열었으며, 본 리뷰에서는 이 기술의 특징, 성능, 잠재적 영향에 대해 살펴볼 것이다.
1. Introduction
메모리는 지능의 핵심 요소로서 맥락에 맞는 효율적 계산을 가능케 하지만, Transformer와 이를 기반으로 한 대규모 언어 모델(LLM)은 어텐션 메커니즘으로 인해 제한된 컨텍스트 의존적 메모리를 가진다. 이 메커니즘은 메모리 사용량과 계산 시간에서 이차적 복잡도를 보여 긴 시퀀스 처리에 제약이 있다.
압축 메모리 시스템은 극도로 긴 시퀀스에 대해 기존 어텐션 메커니즘보다 더 확장 가능하고 효율적일 것으로 예상되며, 고정된 수의 매개변수를 유지하여 제한된 비용으로 정보를 저장하고 복구한다.
본 연구에서는 LLM이 제한된 자원으로 무한히 긴 입력을 처리할 수 있게 하는 Infini-attention이라는 새로운 접근법을 소개한다. 이 기법은 기존 어텐션 메커니즘에 압축 메모리를 통합하고, 단일 Transformer 블록 내에 로컬 및 장기 어텐션 메커니즘을 결합한다.
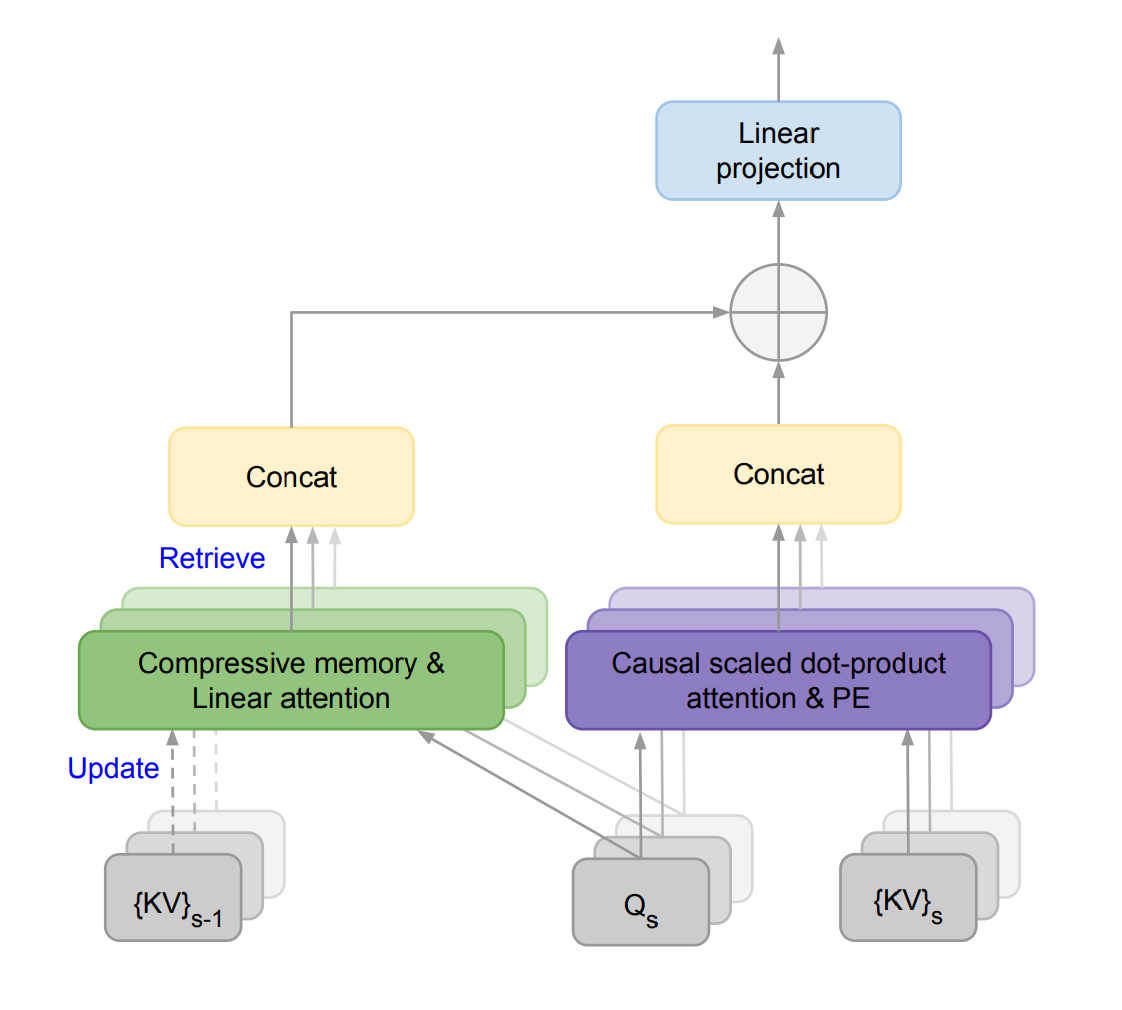
Infini-attention은 표준 어텐션 계산의 모든 상태를 재사용하여 장기 메모리를 통합하고 검색하며, 어텐션의 오래된 Key-Value(KV) 상태를 압축 메모리에 저장하고 후속 처리 시 이를 활용한다. 최종 출력 계산을 위해 장기 메모리에서 검색된 값과 로컬 어텐션 컨텍스트를 집계한다.
실험 결과, Infini-attention은 메모리 크기에서 114배의 압축률을 달성하면서도 긴 컨텍스트 언어 모델링 벤치마크에서 기준 모델을 능가하였다. 1B LLM에 적용 시 1M 시퀀스 길이로 자연스럽게 확장되어 패스키 검색 작업을 해결했으며, 8B 모델에서는 500K 길이의 책 요약 작업에서 새로운 최고 성능(SOTA)을 달성하였다.
2. Infini-attention
infini-attention은 지역적 및 전역적 컨텍스트 상태를 모두 계산하여 이를 출력으로 결합하는 recurrent 어텐션 메커니즘이다. 이는 다중 헤드 어텐션(MHA)과 유사하게 작동한다.
- 특징:
- H개의 어텐션 헤드 수를 유지한다.
- 각 어텐션 레이어마다 H개의 병렬 압축 메모리를 유지한다.
- RNN 및 MNM과 유사하게 긴 시퀀스의 컨텍스트를 효과적으로 추적하기 위한 recurrent memory 상태를 유지한다.
- 수식:
- 어텐션 출력 \(O_s, M_s\) 는 다음과 같이 정의된다: \begin{aligned} O_s,M_S=infini-attention(X_s,M_{s-1}) \end{aligned}
2-1. Scaled Dot-product Attention
Multi-head Scaled Dot-product Attention은 LLM의 주요 구성 블록으로, 특히 self-attention 변형에 많이 사용된다. MHA의 강력한 컨텍스트 의존적 동적 계산 능력과 시간적 마스킹의 편의성이 자기 회귀 생성 모델에서 광범위하게 활용되고 있다.
- 단일 헤드 계산:
- 기본 MHA의 단일 헤드는 입력 시퀀스 \(X \in \mathbb{R}^{N \times d_{\text{model}}}\)로부터 어텐션 컨텍스트 \(A_{\text{dot}} \in \mathbb{R}^{N \times d_{\text{value}}}\)를 다음과 같이 계산한다.
- 어텐션 쿼리, 키 및 값을 다음과 같이 계산한다: \begin{aligned} K = XW_K, \, V = XW_V \, \text{and} \, Q = XW_Q. \end{aligned}
- 여기서, \(W_K \in \mathbb{R}^{d_{\text{model}} \times d_{\text{key}}}\), \(W_V \in \mathbb{R}^{d_{\text{model}} \times d_{\text{value}}}\) 그리고 \(W_Q \in \mathbb{R}^{d_{\text{model}} \times d_{\text{key}}}\)는 학습 가능한 투영 행렬이다.
- 어텐션 컨텍스트 계산:
- 어텐션 컨텍스트는 다른 모든 값들의 가중 평균으로 다음과 같이 계산된다: \begin{aligned} A_{\text{dot}} = \text{softmax} \left( \frac{QK^T}{\sqrt{d_{\text{model}}}} \right) V. \end{aligned}
- MHA의 특징:
- MHA의 경우, 각 시퀀스 요소에 대해 H개의 어텐션 컨텍스트 벡터를 병렬로 계산하고, 이들을 두 번째 차원을 따라 연결한 뒤, 마지막으로 연결된 벡터를 모델 공간으로 투영하여 어텐션 출력을 얻는다.
2-2. Compressive Memory
Infini-attention에서는 새로운 메모리 항목을 생성하는 대신, 쿼리, 키, 값을 재사용하여 압축 메모리를 관리한다. 이 상태 공유는 효율적인 학습 및 추론을 가능하게 하며, 긴 컨텍스트에 대한 적응을 가속화한다.
- 기존 연구 활용:
- 다양한 압축 메모리 형태가 제안되었지만, 본 연구에서는 단순성과 효율성을 위해 associative matrix를 활용한다. (Schlag et al., 2020)
- 이는 메모리 업데이트 및 검색 과정을 단순화하여 선형 어텐션 메커니즘으로 변환할 수 있게 한다.
- 기존 연구에서 제안된 연관 행렬을 활용하여 메모리 업데이트 및 검색 과정을 단순화한다.
Memory retrieval
- 새로운 컨텐츠 \(A_{\text{mem}} \in \mathbb{R}^{N \times d_{\text{value}}}\)는 메모리 \(M_{s-1} \in \mathbb{R}^{d_{\text{key}} \times d_{\text{value}}}\)에서 쿼리 \(Q \in \mathbb{R}^{N \times d_{\text{key}}}\)를 사용하여 검색한다. 검색된 항목은 다음과 같이 표현된다: \begin{aligned} A_{\text{mem}} = \frac{\sigma(Q)M_{s-1}}{\sigma(Q)z_{s-1}}. \end{aligned}
- 여기서, \(\sigma\)와 \(z_{s-1} \in \mathbb{R}^{d_{\text{key}}}\)는 각각 비선형 활성화 함수와 정규화 항이다.
Memory update
- 검색이 완료되면 새로운 KV 항목으로 메모리와 정규화 항을 업데이트한다.
-
새로운 메모리 상태 \(M_s\) 와 \(z_s\)는 다음과 같이 계산된다:
\begin{aligned} M_s \leftarrow M_{s-1} + \sigma(K)^TV \end{aligned} \begin{aligned} z_s \leftarrow z_{s-1} + \sum_{t=1}^{N} \sigma(K_t) \end{aligned} - 이 업데이트된 상태는 다음 세그먼트로 전달되어 각 어텐션 레이어에서 순환 구조를 형성한다.
- \(\sigma(K)^TV\) 항은 연관 바인딩 연산자로 알려져 있다.
Applying delta rule
- 델타 규칙을 Infini-attention에 통합하였다.
- 이 규칙은 새로운 값을 적용하기 전에 기존 값을 검색하고 차감하여 메모리 업데이트를 개선한다.
- 새로운 업데이트 공식: \begin{aligned} M_s \leftarrow M_{s-1} + \sigma(K)^T \left( V - \frac{\sigma(K)M_{s-1}}{\sigma(K)z_{s-1}} \right). \end{aligned}
- 이 방식(Linear + Delta)은 KV 바인딩이 이미 메모리에 있는 경우 연관 행렬을 변경하지 않으면서도 이전 방식(Linear)과 동일한 정규화 항을 유지하여 수치적 안정성을 확보한다.
Long-term context injection
- 로컬 어텐션 상태 \(A_{\text{dot}}\)과 메모리에서 검색된 내용 \(A_{\text{mem}}\)를 학습된 게이팅 스칼라 \(\beta\)를 통해 결합한다: \begin{aligned} A = \text{sigmoid}(\beta) \odot A_{\text{mem}} + \left(1 - \text{sigmoid}(\beta)\right) \odot A_{\text{dot}}. \end{aligned}
- 이 방법은 헤드당 하나의 스칼라 값만 학습 파라미터로 추가하면서 모델의 장기 및 로컬 정보 흐름 사이의 학습 가능한 트레이드오프를 허용한다.
이 모든 메커니즘은 infini-attention이 긴 시퀀스의 컨텍스트를 효과적으로 처리하는 데 기여한다.
Multi head Infini-attention
- 표준 MHA와 유사하게, \(H\)개의 컨텍스트 상태를 병렬로 계산한다.
- 이들을 연결하고 투영하여 최종 어텐션 출력 \(O \in \mathbb{R}^{N \times d_{\text{model}}}\)를 생성한다. \begin{aligned} O = [A^1; \dots ; A^H] W_O \end{aligned}
- 여기서 \(O \in \mathbb{R}^{H \times d_{\text{value}}}\)는 학습 가능한 가중치이다.
- 여기서 \(W_O \in \mathbb{R}^{H \times d_{\text{value}} \times d_{\text{model}}}\)는 학습 가능한 가중치이다.
3. Memory and Effective Context Window

- 무제한 컨텍스트 윈도우: Infini-Transformer는 제한된 메모리 풋프린트를 가지면서도 무제한의 컨텍스트 윈도우를 지원한다.
- 메모리 복잡성:
- Infini-Transformer는 각 헤드에서 압축된 컨텍스트를 저장하기 위해 일정한 메모리 복잡성을 가진다.
- 수식으로는 다음과 같다:
- 상수 메모리 복잡도: \(d_{key} \times d_{value} + d_{key}\)
- 이는 각 층의 각 헤드에서 \(M_s\)와 \(z_s\)에 압축된 컨텍스트를 저장하는 데 사용된다.
- 다른 모델과의 비교:
- 다른 모델들은 시퀀스의 길이가 증가함에 따라 메모리 복잡성이 증가
- Transformer-XL: 캐시 크기에 따른 메모리 복잡성이 증가
- Compressive Transformer, Memorizing Transformers: 소프트 프롬프트 크기와 관련된 메모리 복잡성이 증가
- RMT 및 AutoCompressors: 소프트 프롬프트 크기에 기반한 메모리 복잡성이 증가
4. Experiments
Infini-Transformer 모델의 성능을 평가하기 위해 다음과 같은 긴 입력 시퀀스를 다루는 벤치마크 테스트를 실시하였다:
- 긴 컨텍스트 언어 모델링
- 100만 토큰 길이의 패스키 컨텍스트 블록 검색
- 50만 토큰 길이의 책 요약 작업
언어 모델링 벤치마크에서는 모델을 처음부터 학습하였다. 반면, 패스키 검색 및 책 요약 작업에서는 기존 LLM을 추가 학습하여 긴 컨텍스트에 즉시 적응할 수 있는(플러그 앤 플레이) 능력을 보여주었다.
4-1. Implementation details
세그먼트 청킹
- 전체 입력 텍스트를 Transformer 모델에 전달
- 각 Infini-attention 레이어에서 입력을 세그먼트로 분할
- 각 세그먼트를 개별적으로 처리한 후 다시 재결합하여 원래 길이의 출력을 다음 레이어로 전달
- 이 방식은 기존 Transformer 구조를 최소한으로 수정함
시간별 역전파 (BPTT, Back-propagation through time)
- 각 Infini-attention 층은 시간별 역전파 방식으로 학습
- 압축 메모리 상태에 대한 그래디언트를 계산하는 방식은 RNN 학습과 유사
- 메모리 효율을 위해 세그먼트 처리 시 그래디언트 체크포인트 수행
위치 임베딩 (PE, Position Embeddings)
- 압축 메모리의 Query, Key 벡터에는 위치 임베딩을 사용하지 않음
- 장기 메모리에는 전체적인 컨텍스트 정보만 저장
- 위치 임베딩은 압축 메모리 읽기와 업데이트 후에만 Query, Key 벡터에 적용
4-2. Long-context Language Modeling
실험 설정
- 데이터셋: PG19와 Arxiv-math 벤치마크 사용
- 모델 구조:
- 128차원의 12개 레이어와 8개의 어텐션 헤드
- 4096개의 은닉층을 가진 FFNs(Feed-Forward Network)
- Infini-attention 설정:
- 세그먼트 길이(N):
2048 - 입력 시퀀스 길이:
32768 - 압축 메모리 상태 전개: 16단계
- 세그먼트 길이(N):
실험 결과

- 성능 비교:
- Infini-Transformer가 Transformer-XL과 Memorizing Transformers보다 우수한 성능 달성
- 메모리 효율성: Memorizing Transformers 대비 114배 적은 메모리 파라미터 사용
- 100K 길이 학습 (Arxiv-math):
- 학습 시퀀스 길이:
32K→100K - 결과:
- Linear 모델:
perplexity 2.21 - Linear+Delta 모델:
perplexity 2.20
- Linear 모델:
- 학습 시퀀스 길이:
- 게이팅 점수 시각화
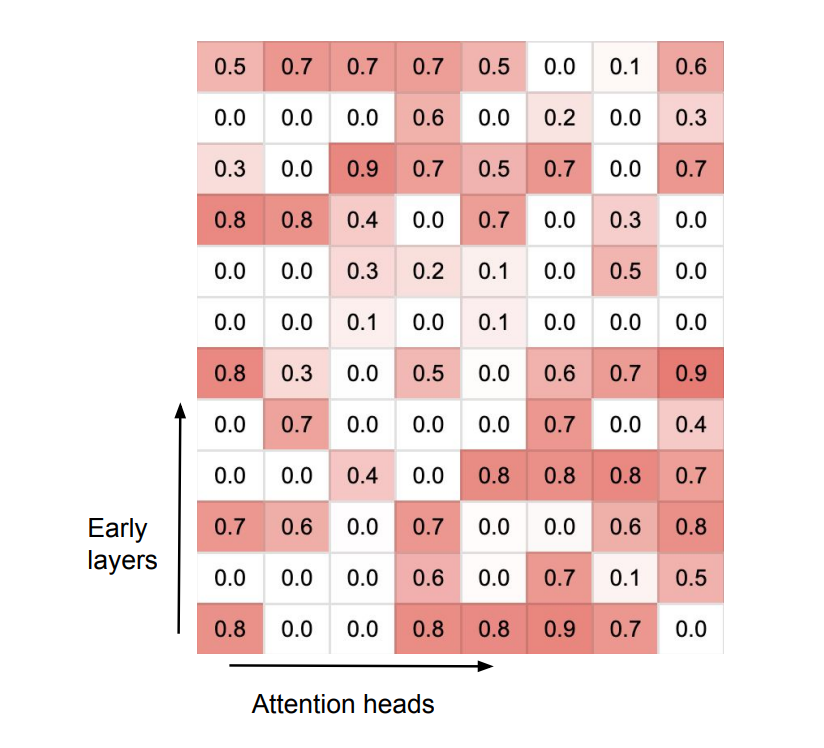
각 레이어의 모든 어텐션 헤드에 대한 압축 메모리의 게이팅 점수 sigmoid(β)를 시각화한 결과, 두 가지 유형의 어텐션 헤드가 관찰됨:
- 전문화된 헤드: 게이팅 점수가 0 또는 1에 가까움
- 로컬 어텐션 계산을 통해 문맥 정보를 처리하거나
- 압축 메모리에서 정보를 검색
- 혼합 헤드: 점수가 0.5에 가까움
- 현재 문맥과 장기 메모리 정보를 하나의 출력으로 통합
흥미롭게도, 각 레이어는 최소한 하나의 단거리 헤드를 가지고 있어 입력 신호가 출력 레이어까지 전달될 수 있다. 또한, 순방향 계산 과정에서 장기 및 단기 콘텐츠 검색이 교차되는 것을 관찰하였다.
- 전문화된 헤드: 게이팅 점수가 0 또는 1에 가까움
4-3. LLM Continual Pre-training
기존 LLM의 긴 문맥 이해력 향상을 위해 경량화된 지속적 사전 학습을 수행하였다. PG19, Arxiv-math, 4K 이상 길이의 C4 텍스트를 학습 데이터로 사용했으며, 모든 실험에서 세그먼트 길이는 2K로 고정하였다.
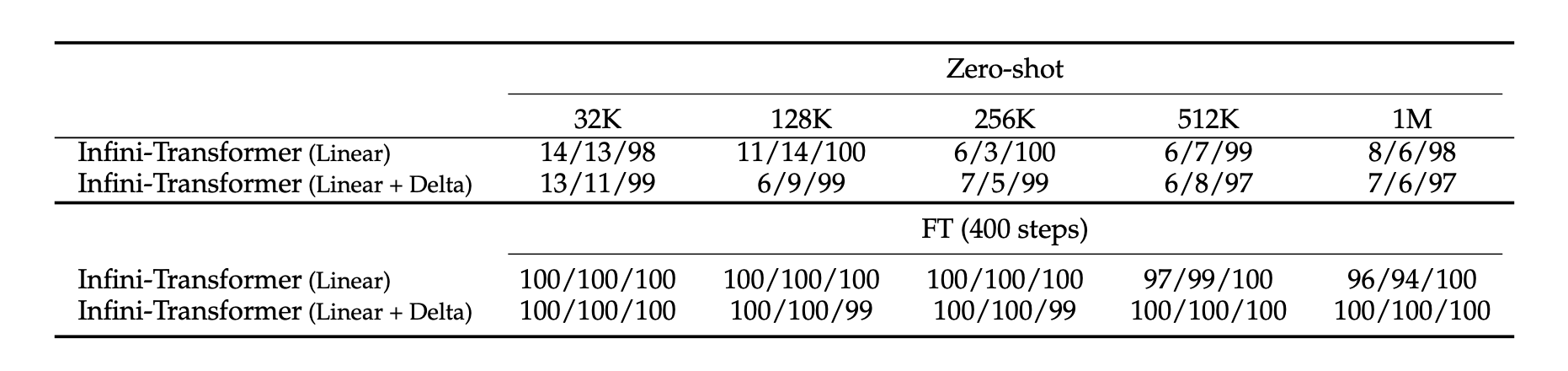
- 1M 패스키 검색 벤치마크
- 방법: 1B LLM의 기본 MHA를 Infini-attention으로 대체, 4K 길이 입력으로 사전 학습
- 목표: 긴 텍스트에 숨겨진 무작위 숫자를 모델이 찾아내는 과제
- 실험 결과: 5K 길이 입력으로 400 스텝 미세 조정 후 1M 길이 문맥까지 처리 가능
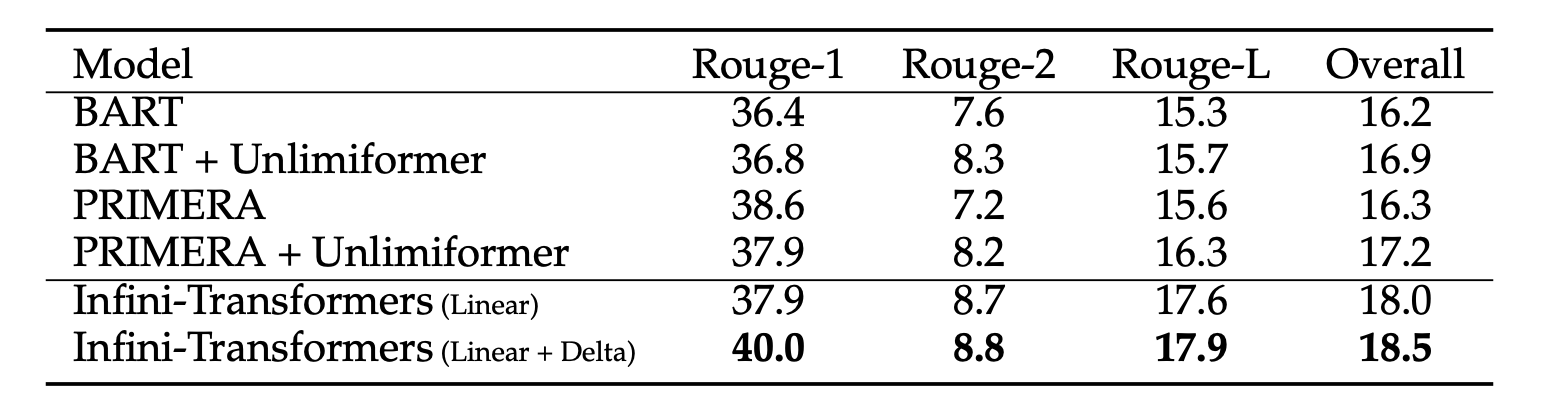
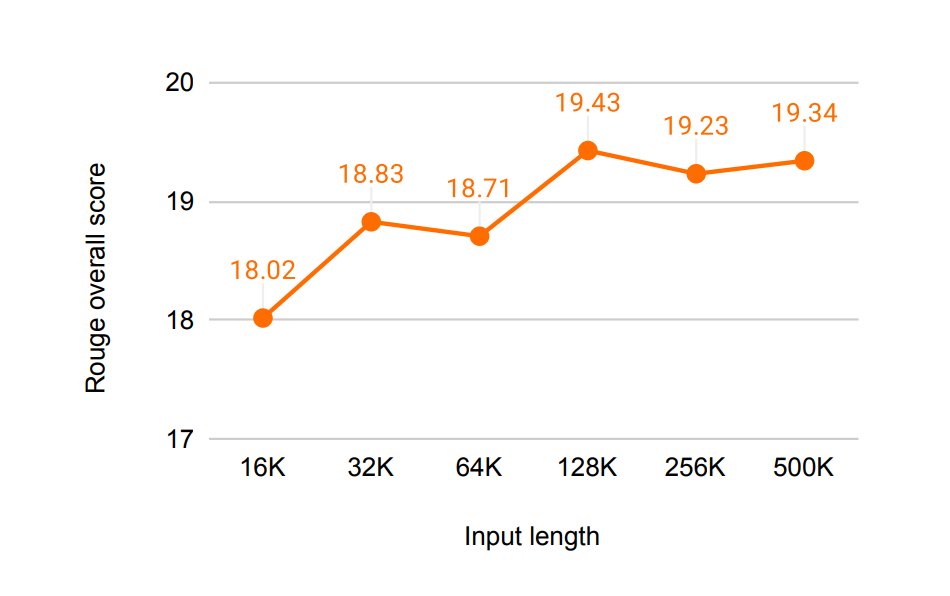
- 500K 길이 책 요약 (BookSum)
- 방법: 8B LLM 모델 사용, 8K 입력 길이로 사전 학습
- 목표: 책의 전체 텍스트 요약 생성
- 설정:
- 미세 조정 시 입력 길이:
32K - 평가 시 입력 길이:
500K - 요약 생성 파라미터:
temperature 0.5,top_p 0.95,decoding step 1024
- 미세 조정 시 입력 길이:
- 주요 성과
- BookSum 태스크에서 최고 성능(SOTA) 달성
- 입력 텍스트 길이가 증가할수록 요약 성능 향상
이 연구는 Infini-Transformers의 긴 컨텍스트 처리 능력과 기존 LLM 모델의 확장성을 보여주며, 특히 1M 길이의 패스키 검색과 500K 길이의 책 요약과 같은 복잡한 태스크에서 우수한 성능을 보여, 긴 문맥을 효과적으로 다룰 수 있음을 입증하였다.
5. Conclusion
Google의 Infini-attention 기술은 LLM의 컨텍스트 윈도우 길이를 획기적으로 확장하는 혁신적인 접근법을 제시하였다. 압축 메모리를 활용해 메모리 효율성을 크게 개선하고, 긴 텍스트 처리 능력을 향상시켰다.
그러나 실제 구현과 실험 과정에서 여러 한계점이 드러났다. 메모리 압축 횟수 증가에 따른 성능 저하, 게이팅 최적화의 어려움, 그리고 예상치 못한 버그 등의 문제가 발견되었다. 현재로서는 Ring Attention, YaRN, rope scaling 등의 기존 방법들이 더 안정적인 성능을 보이는 것으로 평가된다.
이러한 도전과 한계에도 불구하고, Infini-attention은 LLM의 장기 컨텍스트 처리 능력 향상을 위한 중요한 실험적 시도로서 의의가 있으며, 지속적인 연구와 개선을 통해 미래의 LLM 발전에 기여할 수 있는 잠재력을 가지고 있다.