[리뷰] LLM Pruning and Distillation in Practice: The Minitron Approach
Sreenivas, S. T., Muralidharan, S., Joshi, R., Chochowski, M., Patwary, M., Shoeybi, M., Catanzaro, B., Kautz, J., & Molchanov, P. “LLM Pruning and Distillation in Practice: The Minitron Approach” arXiv preprint arXiv:2408.11796, 2024. [paper]
1. Introduce
LLM 제공업체들은 다양한 크기(ex. Llama 3.1 8B, 70B, 405B)의 모델 패밀리를 개발하여 사용자들의 다양한 요구를 충족시킨다. 그러나 이러한 접근 방식은 상당한 자원을 필요로 한다.
최근 연구에 따르면, 가중치 가지치기와 지식 증류를 결합하여 LLM 모델 패밀리 학습 비용을 크게 절감할 수 있다. 이 방법은 가장 큰 모델만 처음부터 학습시키고, 나머지 모델들은 이를 가지치기한 후 지식 증류를 통해 정확도를 복원한다.
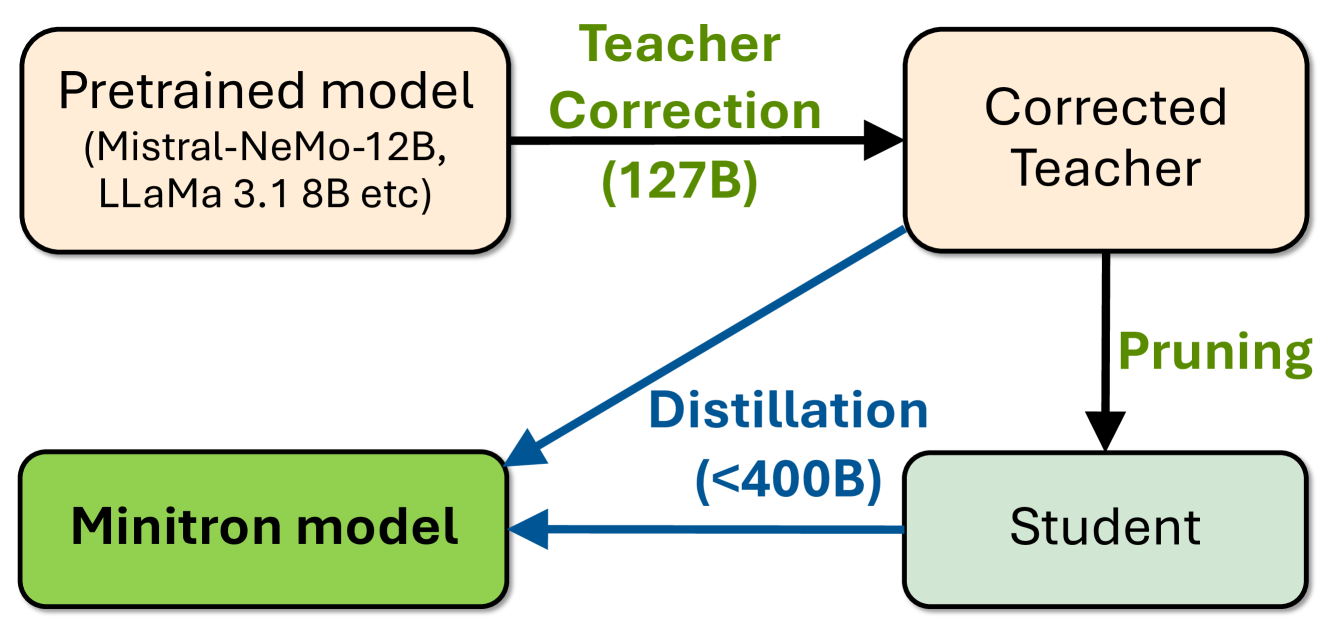
본 연구에서는 Minitron 압축 전략을 Llama 3.1 8B와 Mistral NeMo 12B 모델에 적용하여 각각 4B와 8B 매개변수로 압축하였다. 원본 학습 데이터에 접근할 수 없어, ‘교사 보정(teacher correction)’ 단계를 도입하여 교사 모델(teacher model)을 자체 데이터셋으로 파인 튜닝하였다.
2. Methodology
본 연구에서는 대규모 언어 모델(LLM)의 효율적인 압축 방법을 제시한다. 이 방법은 가지치기와 지식 증류를 결합하여 모델의 크기를 줄이면서도 성능을 유지하는 것을 목표로 한다.
접근 방식 개요
- 교사 보정: 증류에 사용될 데이터셋으로 교사 모델을 파인 튜닝
- 가지치기: 모델의 크기를 축
- 지식 증류: 가지치기로 인한 정확도 손실을 복구
가지치기 기법
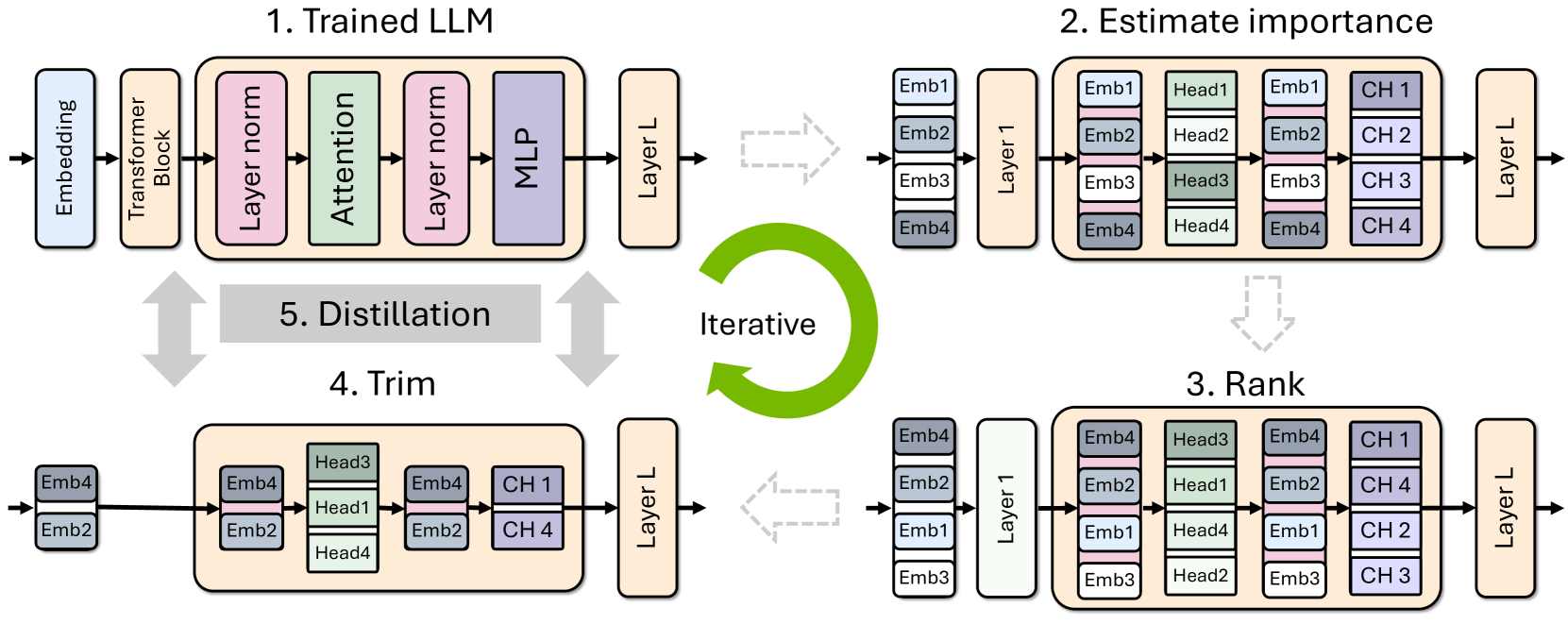
가지치기는 모델의 크기를 줄이는 효과적인 기술이다. 여기서는 구조화된 가지치기 방식을 사용하여 모델의 특정 부분을 제거한다.
- 구조화된 가지치기: 모델 가중치에서 0이 아닌 요소들의 블록을 한 번에 제거
- 중요도 추정: 모델의 각 층, 뉴런, 어텐션 헤드, 임베딩 차원의 중요도를 평가
- 활성화 기반 전략: 작은 보정 데이터셋(1024 샘플)을 사용하여 각 요소의 중요도를 계산
- 깊이 가지치기: LM 검증 손실, 블록 중요도(Block Importance, BI), 다운스트림 작업 정확도를 고려하여 층의 중요도를 평가
- 모델 트리밍: 계산된 중요도에 따라 가중치 행렬을 직접 트리밍(재구성)함
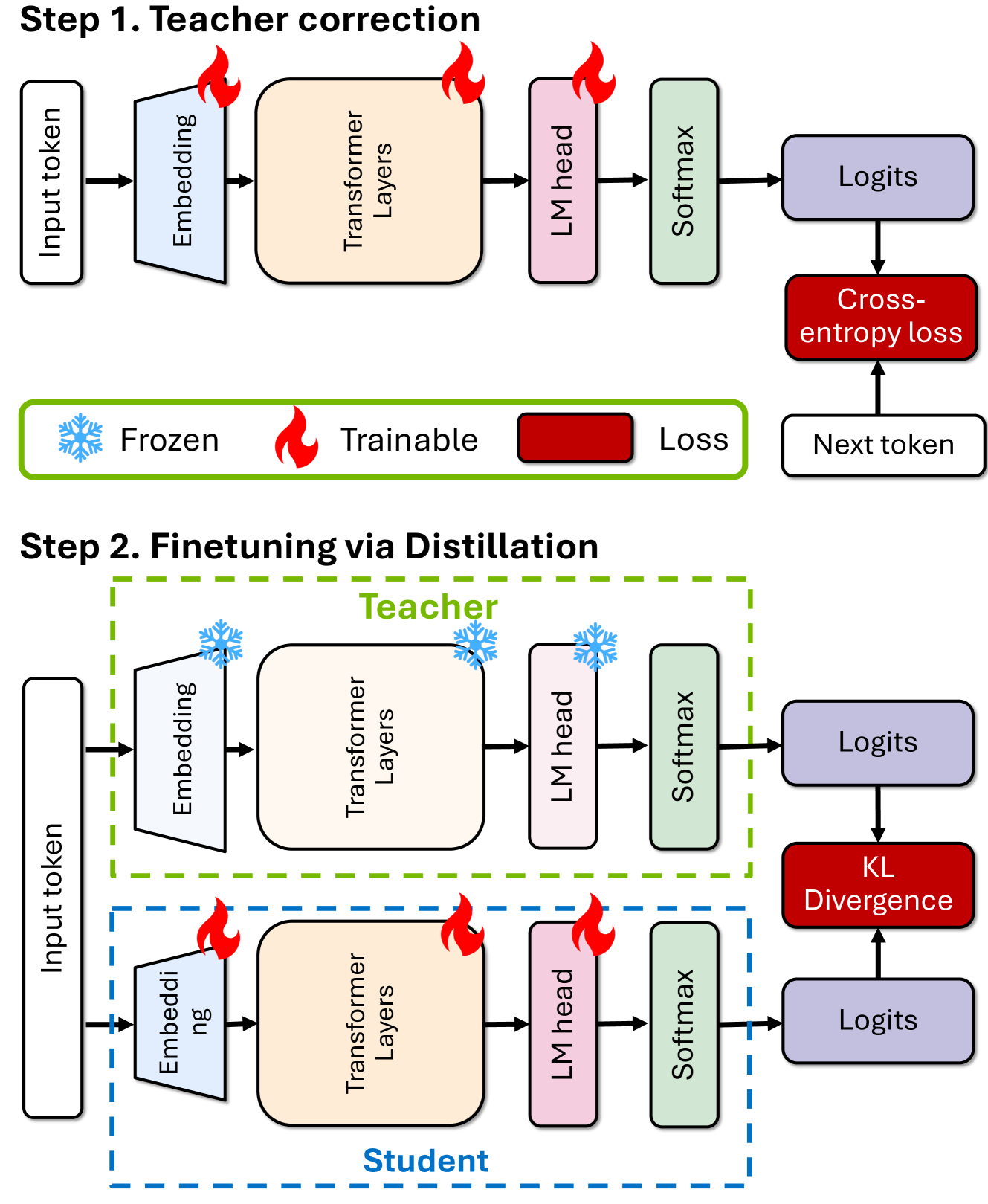
증류를 통한 재학습
가지치기 후 모델의 정확도를 복구하기 위해 두 가지 재학습 전략을 사용한다:
- 실제 레이블을 사용한 기존 학습
- 지식 증류(Knowledge Distillation, KD) 방식
- 교사 모델(원본 모델)의 지식을 학생 모델(가지치기된 모델)로 전달
- 교사와 학생 모델의 로짓(모델의 최종 출력 직전 값)에 대해 순방향 KL 발산 손실을 사용
이 접근 방식은 LLM의 효율적인 압축과 성능 유지를 동시에 달성할 수 있게 한다. 가지치기를 통해 모델 크기를 줄이고, 지식 증류를 통해 정확도를 복구함으로써 계산 효율성과 모델 성능 사이의 균형을 이룬다.
3. Training Details
3-1. Pre-training
- Llama 3.1 8B와 Mistral NeMo 12B는 각각 독점 데이터셋으로 사전 학습되었다.
- Llama 3.1 8B 모델은 15T 토큰으로 학습되었다.
- 본 연구에서는 Hugging Face에서 공개된 Base 모델을 사용한다.
- 모든 실험에는 Nemotron-4에서 선별한 연속 학습 데이터셋(CT)을 활용한다.
3-2. Pruning
- Minitron 논문의 최선의 방법을 기반으로 한 간소화된 가지치기 레시피를 사용한다.
- 너비 가지치기: l2-norm과 평균을 집계 함수로 사용하며, 단일 샷 가지치기를 수행한다.
- 깊이 가지치기: Winogrande에서 정확도 하락이 가장 적은 연속적인 층을 제거한다.
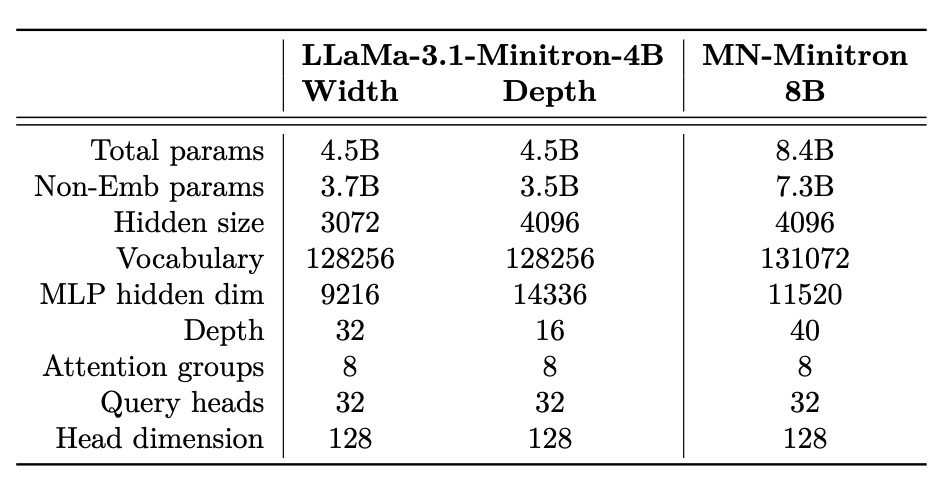
- Llama-3.1-Minitron-4B와 MN-Minitron-8B에 대해 수동 아키텍처 구성을 사용한다.
3-3. Distillation
교사 보정(Teacher Correction):
- 교사 모델을 약 127B 토큰을 사용하여 데이터셋에 파인 튜닝한다.
- 이는 원본 학습 데이터셋과 증류 데이터셋 간의 토큰 분포 차이를 보완하기 위함이다.
재학습(Retraining):
- 로짓 전용 증류를 사용하여 교사와 학생 확률 간의 KL 발산 손실을 최소화한다.
- LM 교차 엔트로피 손실은 무시한다.
- 32개의 NVIDIA DGX H100 노드를 사용하여 학습을 수행한다.
3-4. Instruction Tuning
- Llama-3.1-Minitron 4B 모델에 대해 NeMo-Aligner를 사용하여 supervised fine-tuning(SFT)을 수행한다.
- instruction-following 및 역할 수행(IFEval, MT-Bench), RAG QA(ChatRAG-Bench), function-calling 기능(BFCL)에 대해 평가한다.
4. Analysis
본 연구에서는 새로운 압축 모델들의 특성을 더 잘 이해하기 위해 다양한 실험을 수행했다. 주요 결과는 다음과 같다:
- 너비 vs 깊이 가지치기:
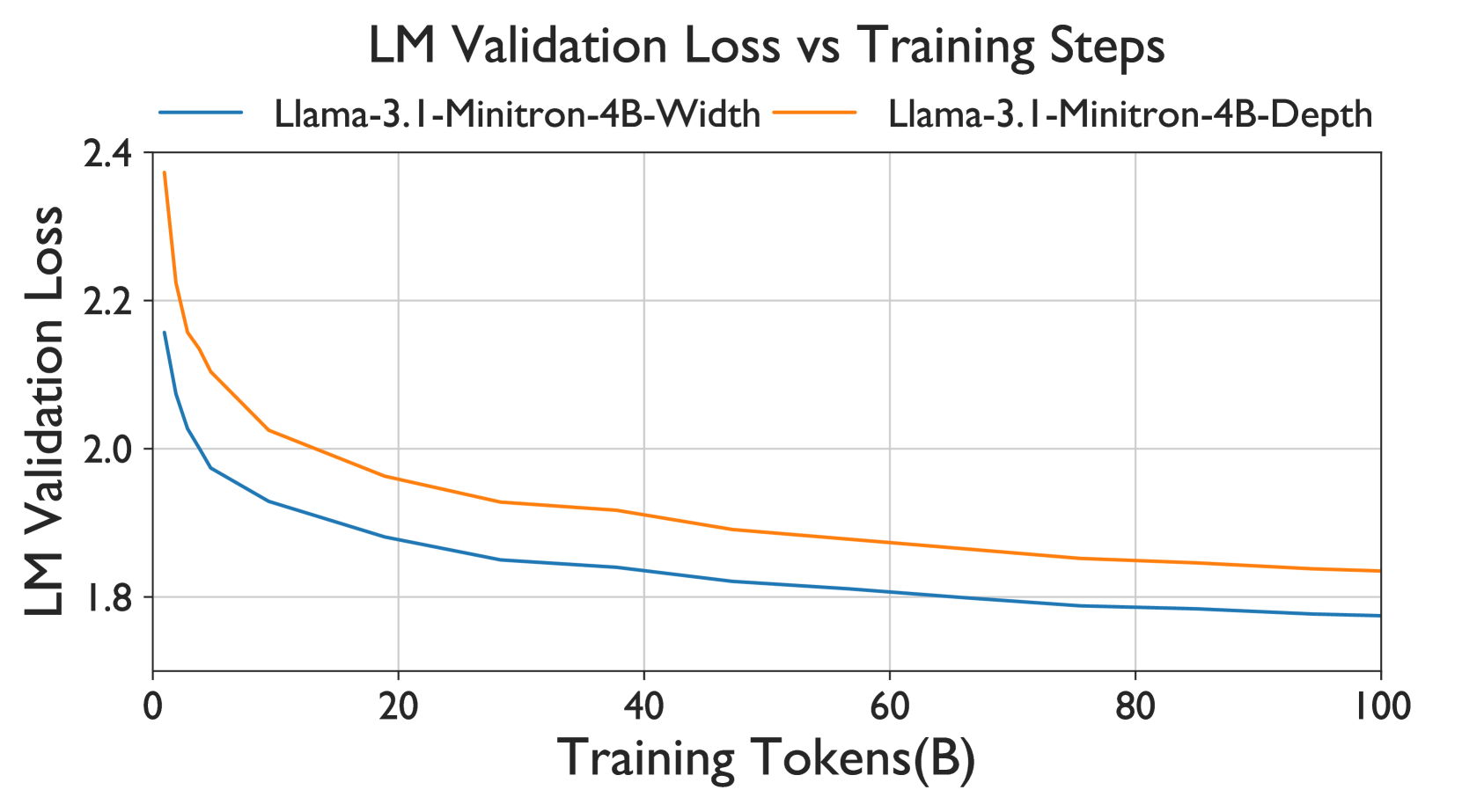
결과:
- Llama-3.1-Minitron-4B 모델에 대해 너비와 깊이 가지치기를 비교했다.
- 동일한 매개변수 수에도 불구하고, 너비 가지치기가 더 나은 성능을 보였다.
- 너비 가지치기는 초기 손실이 더 작고, 전반적으로 더 우수한 성능을 보였다.
- 가지치기와 증류의 효과:
- 무작위 가중치 초기화 및 증류
- 무작위 가지치기 및 증류
- 제안된 가지치기 + 일반적인 LM 손실 학습
- 제안된 가지치기 + 증류 기반 학습
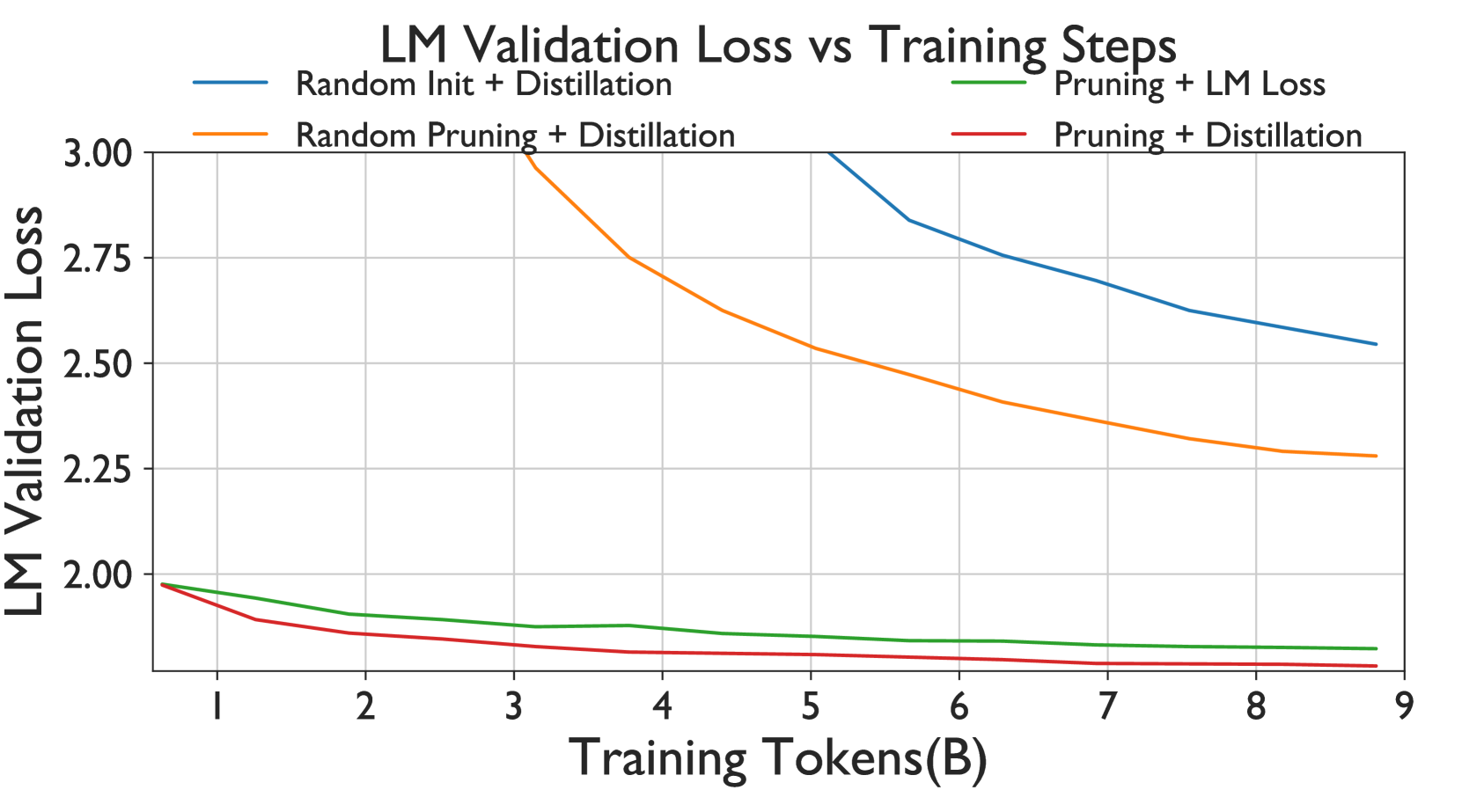
결과:
- 가지치기는 무작위 초기화보다 훨씬 더 나은 시작점을 제공한다.
- 증류 기반 학습은 기존 학습 방법보다 적은 학습 토큰으로도 더 나은 성능을 보였다.
- 교사 보정:
- 보정된 교사를 가지치기하고 증류
- 원래 교사를 가지치기하고 보정된 교사로부터 증류

결과:
- 교사 보정은 가지치기의 최적성에 영향을 미치지 않는다.
- 보정된 교사로부터의 증류가 중요한 역할을 한다.
- 교사 보정은 증류와 함께 사용될 때 성능 격차를 줄일 수 있다.
- 깊이 가지치기 지표:
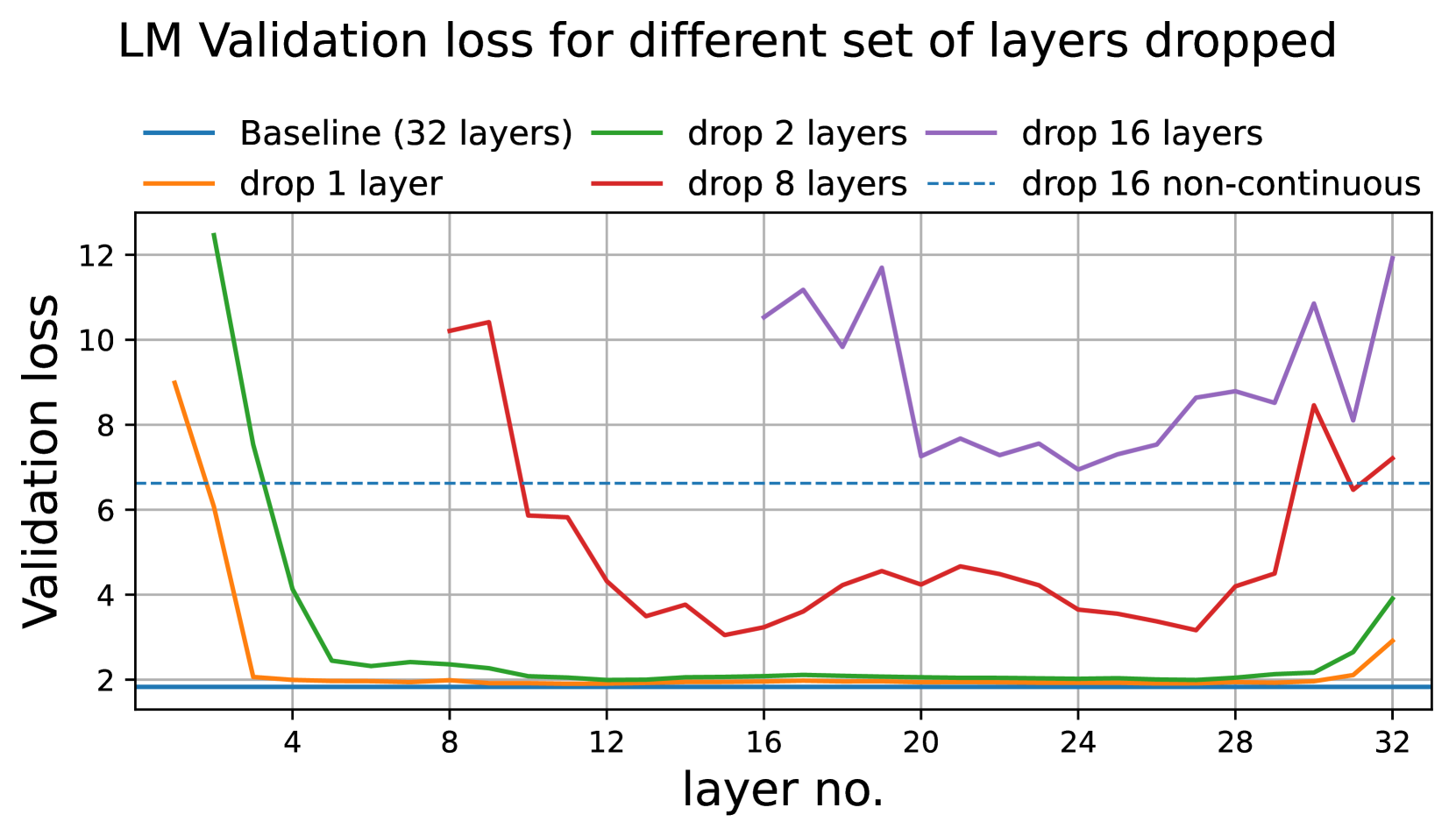
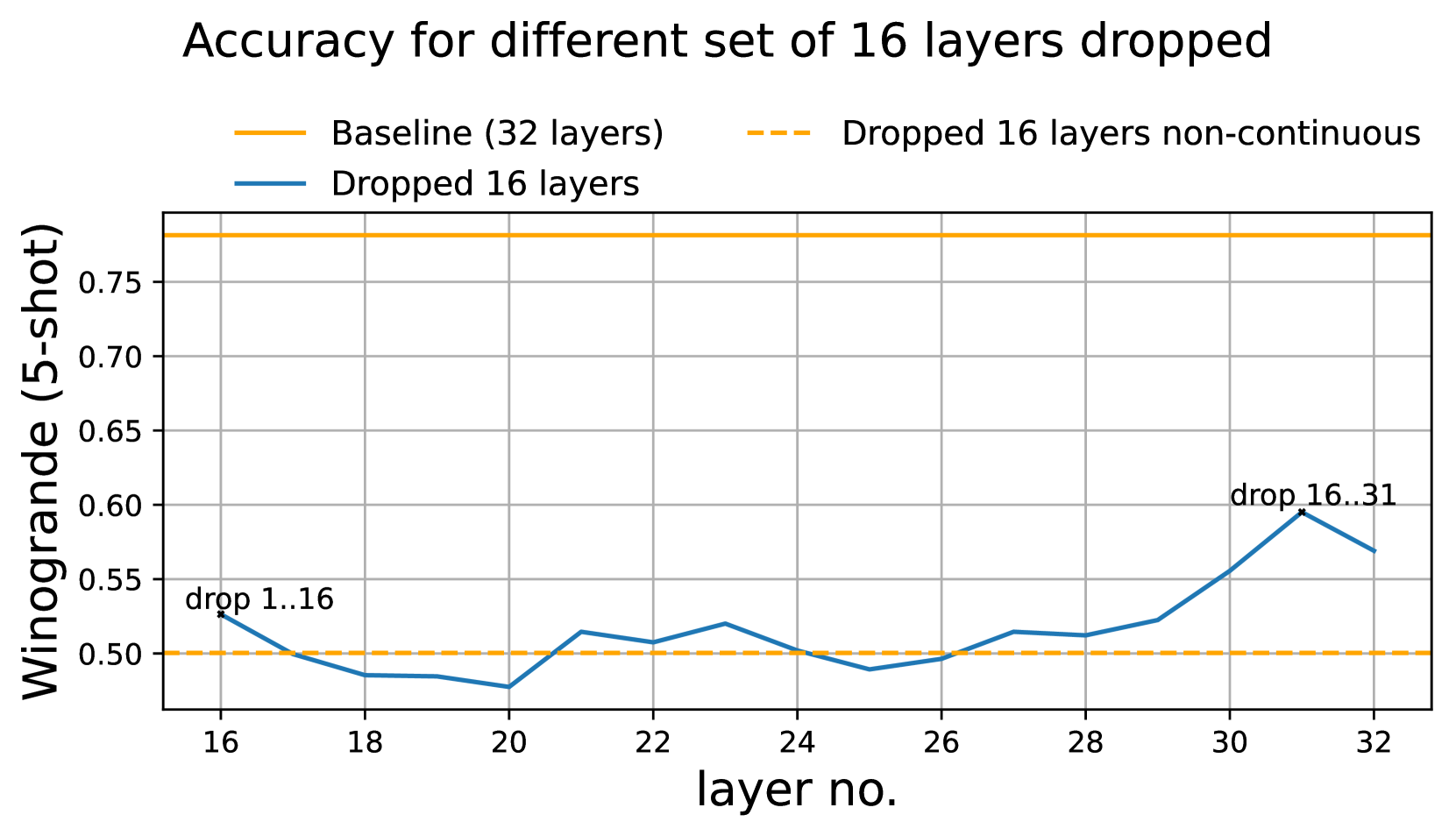
결과:
- LM 검증 손실 분석 결과, 모델의 시작과 끝 부분의 층들이 가장 중요한 것으로 나타났다.
- 비연속적인 층 제거가 연속적 층 제거보다 LM 검증 손실 측면에서는 더 나은 결과를 보였다.
- 단, 다운스트림 작업 성능에서는 이 패턴이 항상 유지되지 않았다.
- Winogrande 작업에서는 연속적인 층 제거가 더 나은 성능을 보였다.
5. Evaluation
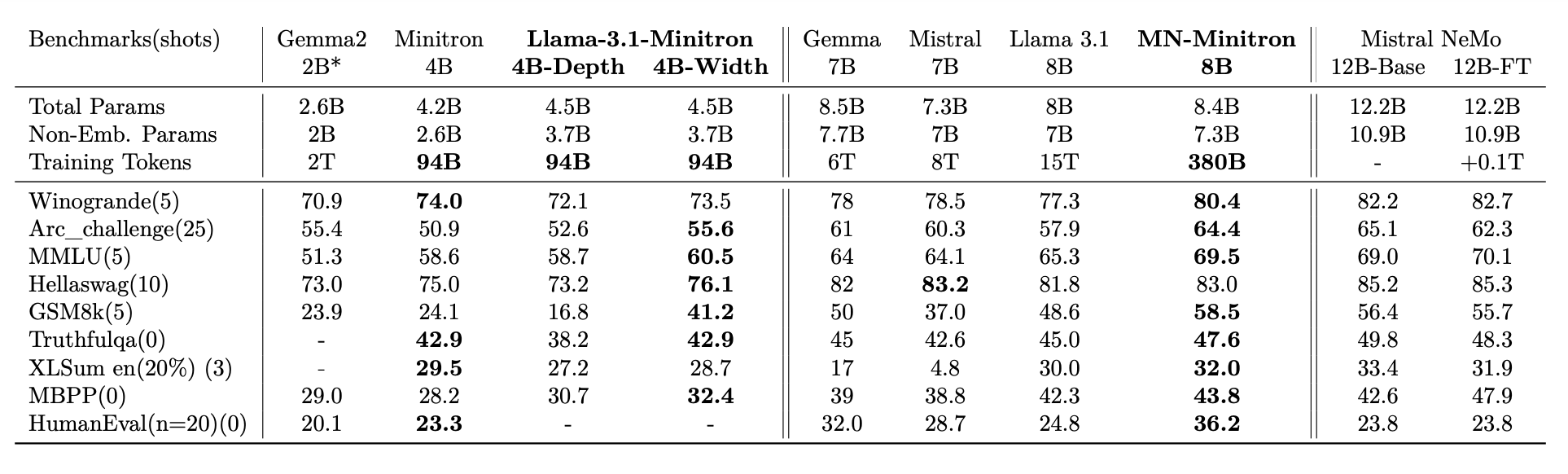
기본 모델 평가 결과
- MN-Minitron-8B:
- Llama 3.1 8B보다 우수한 성능
- 40배 적은 학습 토큰 사용 (380B vs. 15T)
- Llama-3.1-Minitron 4B:
- Llama 3.1 8B에 근접한 성능
- 150배 적은 학습 토큰 사용 (94B vs. 15T)
- 이전 세대 Minitron 4B보다 우수한 성능
- 너비 가지치기 모델이 깊이 가지치기 모델보다 전반적으로 우수한 성능 보임
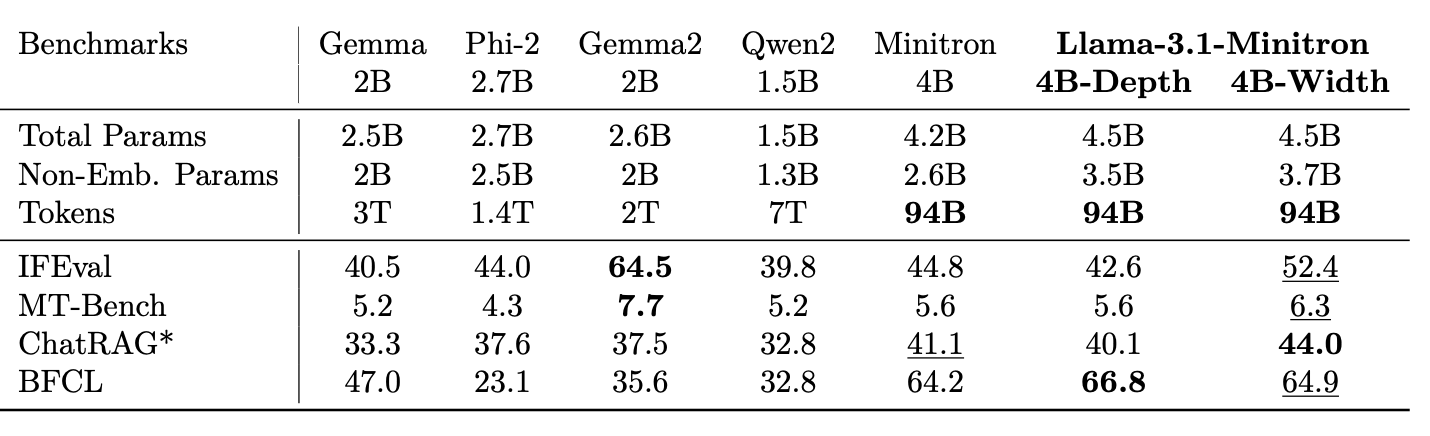
지시 모델 평가 결과
- Llama-3.1-Minitron 4B 변형들:
- 강력한 지시 따르기 및 역할 수행 능력 보유
- IFEval과 MT-Bench에서만 Gemma2에 뒤쳐짐
- ChatRAG-Bench(검색 기반 질문 응답)와 BFCL(함수 호출)에서 최고 수준의 성능 달성
Insights
- 일반적인 통찰:
- 교사 보정의 중요성:
- 새로운 데이터셋에서 증류 효과를 최적화하기 위해 중요함
- 증류에 사용된 데이터셋으로 교사 모델을 파인 튜닝하면 LM 검증 손실이 6% 이상 감소
- 가지치기의 최적성에는 영향을 미치지 않으며, 증류와 동시에 수행 가능
- 효율적인 학습:
- 380B 토큰만으로 최첨단 정확도 달성 (Minitron 논문의 결과와 일치)
- 너비 가지치기 전략:
- 주의 헤드를 유지하고 다른 차원(MLP 중간 차원, 임베딩 채널)을 가지치기하여 더 높은 정확도 달성
- 교사 보정의 중요성:
- Mistral NeMo 12B에서 MN-Minitron-8B로 압축:
- 압축 모델이 일부 벤치마크에서 교사 모델 능가
- GSM8k:
55.7%→58.5% - HumanEval:
23.8%→36.2%
- GSM8k:
- 이러한 개선은 데이터셋의 영향을 받았을 가능성 있음
- 재학습은 증류 손실만을 사용하여 수행됨
- 압축 모델이 일부 벤치마크에서 교사 모델 능가
- Llama 3.1 8B에서 Llama-3.1-Minitron 4B로 압축:
- 정확도 측면:
- 너비 가지치기:
MMLU 60.5%,GSM8K 41.24% - 깊이 가지치기:
MMLU 58.7%,GSM8K 16.8%
- 너비 가지치기:
- 속도 향상:
- 깊이 가지치기: 2.7배 속도 향상
- 너비 가지치기: 1.7배 속도 향상
- 깊이 가지치기 전략: 연속적 층 제거가 비연속적 제거보다 효과적
- 정확도 측면:
요약:
- 너비 가지치기: 정확도 측면에서 우수
- 깊이 가지치기: 속도 향상 측면에서 우수
- 교사 보정과 증류 조합: 모델 성능 최적화에 중요
- 가지치기 전략: 모델 구조와 목표에 따라 다르게 적용 필요
6. Conclusion
본 연구는 대규모 언어 모델(LLM)의 효율적인 압축 방법을 제시하고 그 효과를 검증하였다. 가중치 가지치기와 지식 증류를 결합한 이 방법은 모델 크기를 크게 줄이면서도 성능을 유지할 수 있음을 입증했으며, Llama 3.1 8B와 Mistral NeMo 12B 모델을 각각 4B와 8B로 성공적으로 압축하였다.
교사 보정이 새로운 데이터셋에서 증류 효과를 최적화하는 데 중요한 역할을 한다는 점이 밝혀졌으며, 이는 LM 검증 손실을 6% 이상 감소시키는 효과를 보였다. 또한, 380B 토큰만으로 최첨단 정확도를 달성할 수 있었는데, 이는 원본 모델 훈련에 사용된 토큰 수의 1/40에 불과한 양이다.
가지치기 전략 비교에서는 너비 가지치기가 정확도 측면에서, 깊이 가지치기가 속도 향상 측면에서 각각 우수한 성능을 보였다. 압축된 모델들의 성능 평가 결과, MN-Minitron-8B는 일부 벤치마크에서 원본 교사 모델을 능가했으며, Llama-3.1-Minitron 4B는 원본 모델에 근접한 성능을 보이면서 처리 속도가 향상되었다.
지시 모델 평가에서는 압축된 모델들이 강력한 instruction-following 및 역할 수행 능력을 보유했으며, 특히 검색 기반 질문 응답과 함수 호출 작업에서 최고 수준의 성능을 달성하였다.
이러한 결과는 LLM 압축 기술이 모델의 크기를 줄이면서도 성능을 유지하거나 심지어 향상시킬 수 있음을 보여준다. 향후 연구에서도 지식 증류 사례와 결합된 구조화된 가중치 제거에 대한 추가 작업이 계획되어 있으며 이를 NVIDIA NeMo 프레임워크에서 점진적으로 출시할 계획이라고 한다.