[리뷰] Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
Sapkota Ranjan, et al. “Vision-Language-Action Models: Concepts, Progress, Applications and Challenges” arXiv preprint arXiv:2505.4769, 2025. [paper]
이 논문은 지난 3년간 Vision-Language-Action(VLA) 모델이 어떻게 로봇 공학의 판도를 바꾸었는지 종합적으로 분석합니다. 과거에는 ‘보고’, ‘이해하고’, ‘움직이는’ 기능이 분리되어 있던 로봇 시스템이, VLA의 등장으로 이 세 가지를 하나의 프레임워크로 통합하여 “저기 사과 좀 가져다줘”와 같은 복잡한 명령을 실제 행동으로 옮길 수 있게 되었습니다. 하지만 아직 실시간 추론 속도가 느리고, 안전성을 보장하기 어려우며, 새로운 환경에 대한 일반화 능력이 부족한데다 시스템이 너무 복잡하고 무겁다는 명확한 한계에 직면해 있습니다. 논문은 이러한 과제들을 해결하고, 스스로 학습하고 적응하는 에이전트 AI(Agentic AI) 기술과 융합하는 것이, 로봇을 단순한 기계를 넘어 인간과 함께하는 진정한 지능형 파트너로 만드는 핵심적인 미래 방향이라고 결론짓습니다.
- Introduction
- Concepts of Vision-Language-Action Models
- Progress in Vision-Language-Action Models
- Challenges and Limitations of Vision-Language-Action Models
- Discussion
- Conclusion
1. Introduction
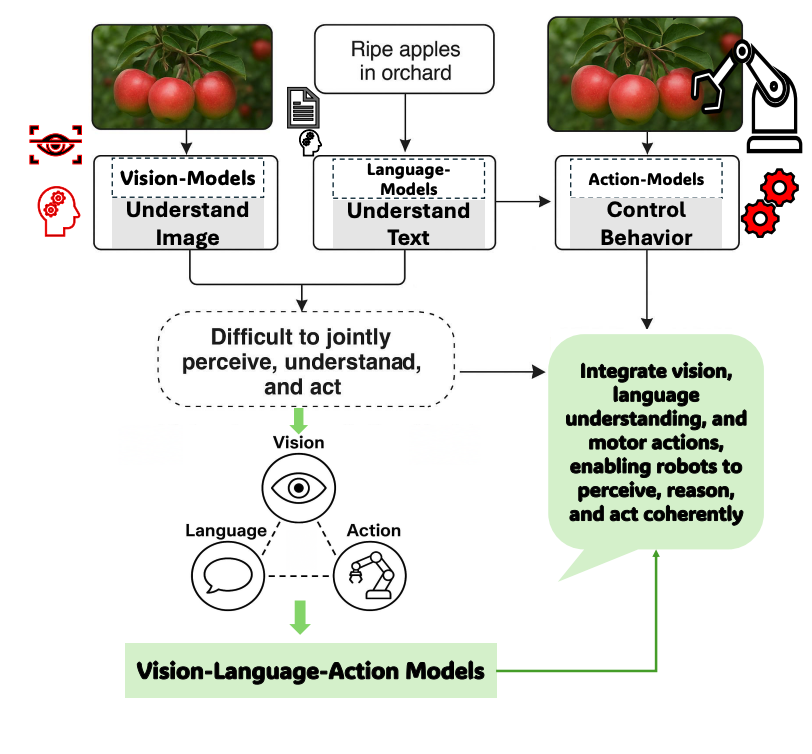
과거 인공지능 및 로보틱스 분야의 발전은 이미지를 인식하는 비전(Vision), 텍스트를 이해하는 언어(Language), 그리고 움직임을 제어하는 액션(Action) 시스템이 각기 독립적으로 개발되는 방식으로 이루어졌습니다. 이러한 시스템들은 각자의 영역에서는 뛰어난 성능을 보였지만, 서로 연동하여 복잡한 문제를 해결하거나 예측 불가능한 새로운 상황에 유연하게 대처하는 데에는 명백한 한계를 드러냈습니다. 그 결과, 시각 정보를 언어적 이해와 결합하여 실제 행동으로 옮기는 통합적인 지능을 구현하지 못하는 ‘통합 격차(integration gap)‘가 중요한 기술적 병목 현상으로 자리 잡았습니다.
이러한 근본적인 한계를 극복하기 위해, 비전, 언어, 액션을 단일 프레임워크 안에서 통합하는 VLA(Vision-Language-Action) 모델이 혁신적인 해결책으로 등장했습니다. VLA 모델은 로봇의 물리적 움직임을 ‘액션 토큰‘이라는 데이터 형태로 변환하여, 시각 및 언어 정보와 함께 학습시키는 방식을 채택했습니다. 이로써 로봇은 단순히 사물을 보거나 명령어를 이해하는 것을 넘어, 주변 환경을 종합적으로 인식하고 복잡한 지시를 추론하여 그에 맞는 행동을 동적으로 생성하고 실행할 수 있게 되었습니다. 이 방법론적 혁신은 로봇이 처음 보는 물체나 새로운 명령에도 효과적으로 일반화하는 능력을 크게 향상시키며, 진정한 의미의 자율 지능 구현에 한 걸음 더 다가섰습니다.
VLA 모델이 AI 로보틱스 분야에 가져온 패러다임의 전환은 매우 중요하기에, 본 논문은 이 기술에 대한 체계적이고 비판적인 검토를 수행하고자 합니다. VLA의 핵심 개념과 아키텍처 원칙을 명확히 하고, 기술 발전의 궤적을 추적하며, 데이터 효율성, 안전, 윤리 등 현재 직면한 과제들을 심도 있게 분석할 필요가 있습니다. 이를 통해 VLA 기술의 현주소를 진단하고 미래 연구 방향을 제시하여, 더욱 강력하고 효율적이며 신뢰할 수 있는 시스템 개발에 기여하는 것이 본 논문의 궁극적인 목표입니다.
이를 위해 본 논문은 아래의 3가지 핵심 영역을 중심으로 VLA 모델을 체계적으로 분석할 것입니다.
- 1부: 개념적 기초 (Conceptual Foundations)
- VLA 모델의 구성 요소, 역사적 진화, 멀티모달 통합 메커니즘, 토큰화 및 인코딩 전략 등 핵심 개념을 상세히 다룸.
- 2부: 최근 기술 발전 동향 (Recent Progress)
- 최신 아키텍처 혁신, 데이터 효율적 학습 프레임워크, 파라미터 효율적 모델링, 모델 가속화 전략 등 실용화를 위한 기술적 발전을 통합적으로 제시.
- 3부: 현재의 한계와 미래 과제 (Current Limitations)
- 추론 병목 현상, 안전 문제, 높은 연산 비용, 제한된 일반화, 윤리적 함의 등 VLA 시스템이 직면한 문제를 포괄적으로 논의하고 잠재적 해결책을 제시.
2. Concepts of Vision-Language-Action Models
VLA 모델은 기술적으로 이 모델들은 비전 인코더, 언어 모델, 그리고 행동을 결정하는 정책 모듈을 융합하여 작동하며, cross-attention이나 임베딩 결합 같은 기법을 통해 시각 정보와 언어 지시를 정밀하게 연계합니다. 기존의 분절된 로봇 시스템과 달리 VLA는 의미론적 이해를 바탕으로 상황을 추론하고, 물체의 사용 가능성(affordance)을 감지하며, 시간적 계획을 수립할 수 있습니다. 예를 들어, “빨간 사과를 집어라”와 같은 언어적 목표가 주어지면, VLA 모델은 카메라로 환경을 관찰하고 그 의미를 해석하여 구체적인 행동 순서를 출력하며, 이 모든 과정은 분리된 하위 시스템이 아닌 end-to-end 학습을 통해 이루어집니다.
2.1. Evolution and Timeline
VLA 모델의 발전 과정은 2022년부터 2025년까지 크게 세 가지 뚜렷한 단계로 구분할 수 있습니다.
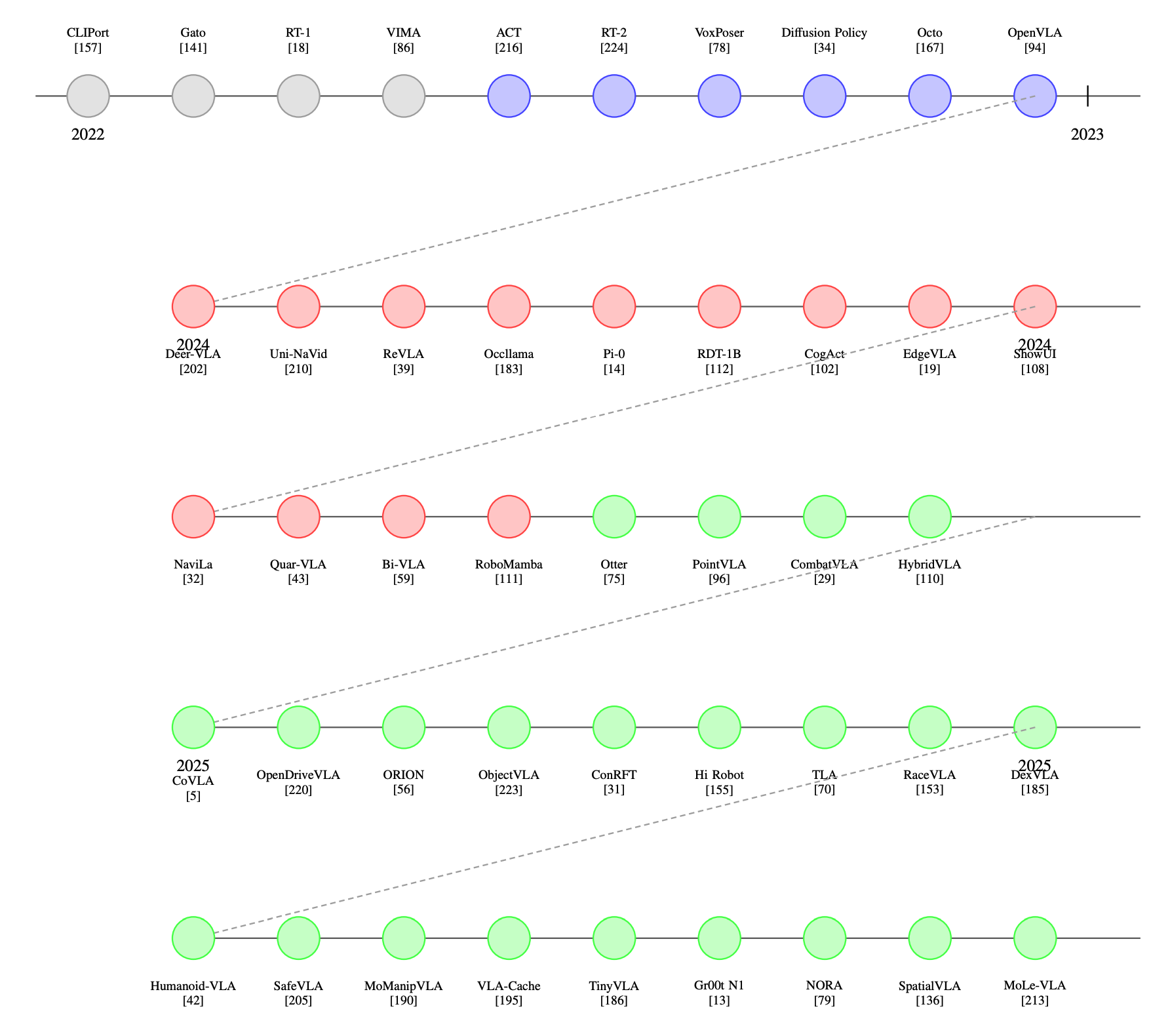
1. 1단계: 기초 통합 (Foundational Integration, 2022–2023)
- 목표: multimodal fusion 아키텍처를 통해 기본적인 시각-운동 능력(visuomotor coordination)을 확립
- 주요 연구 및 성과:
- CLIPort: CLIP 임베딩과 모션 기본 요소를 최초로 결합
- Gato: 604개 작업에서 범용적인 성능 입증
- RT-1: 대규모 모방 학습으로 높은 조작 성공률(97%) 달성
- VIMA: 트랜스포머 기반 플래너로 시간적 추론 도입
- RT-2, ACT: 시각적 연쇄 사고(visual chain-of-thought) 추론 및 어포던스 기반(affordance grounding) 개념 도입
- Diffusion Policy: 확산 모델(diffusion process)을 통한 확률적 행동 예측
- 한계: 저수준 제어에 집중되어 있어, 복잡한 조합적 추론(compositional reasoning) 능력이 부족하였음
2. 2단계: 전문화 및 구체화된 추론 (Specialization and Embodied Reasoning, 2024)
- 목표: 특정 도메인에 맞는 귀납적 편향(inductive biases)을 통합하여 성능 최적화
- 주요 연구 및 성과:
- Deer-VLA: 검색 증강 훈련으로 퓨샷(few-shot) 적응 능력 향상
- Uni-NaVid: 3D 장면 그래프를 통합하여 내비게이션 성능 최적화
- ReVLA: 가역 아키텍처(reversible architecture)로 메모리 효율성 개선
- Occllama: 물리 정보 기반 어텐션으로 부분적 관찰 문제(partially observable) 해결
- 자율주행: 멀티모달 센서 융합으로 적용 분야 확장
3. 3단계: 일반화 및 안전이 중요한 배포 (Generalization and Safety-Critical Deployment, 2025)
- 목표: 시스템의 견고성(robustness)과 인간 정렬(human-alignment)을 최우선으로 고려
- 주요 연구 및 성과:
- SafeVLA: 공식 검증(formal verification)을 통합하여 위험 인식 결정 능력 확보
- Humanoid-VLA: 계층적 VLA를 통해 전신 제어(whole-body control) 입증
- MoManipVLA: 임베디드 배포를 위한 컴퓨팅 효율성 최적화
- Groot N1: Sim-to-real 전이 학습으로 현실 적용 문제 해결
- ShowUI: 자연어 기반으로 인간-루프(human-in-the-loop) 인터페이스 연결
2.2. Multimodal Integration: From Isolated Pipelines to Unified Agents
VLA 모델의 핵심적인 발전은 비전, 언어, 액션을 하나의 통합된 아키텍처 내에서 공동으로 처리하는 멀티모달 통합 능력에 있습니다. 과거의 전통적인 로봇 시스템은 인식, 자연어 이해, 제어 기능을 각각 독립된 모듈로 취급하고, 이를 수동으로 정의된 인터페이스를 통해 연결했습니다. 이러한 분절된 파이프라인 구조는 적응성이 부족하여 새로운 환경이나 모호한 지시에 대처하기 어려웠고, 사전에 정의된 틀을 벗어나는 명령을 일반화하지 못하는 명백한 한계를 가졌습니다.
이와 대조적으로, 최신 VLA 모델은 대규모 사전 훈련된 인코더와 트랜스포머 기반 아키텍처를 활용하여 여러 데이터 양식(modality)을 end-to-end로 융합합니다. 예를 들어, “잘 익은 빨간 사과를 집어라”(Figure 5)라는 명령이 주어지면, 비전 인코더는 장면 속 객체와 그 속성을 파악하고 언어 모델은 명령어의 의미를 벡터로 변환합니다. 이후 두 정보는 cross-attention과 같은 기술을 통해 하나의 통합된 잠재 공간으로 결합되어, 상황에 맞는 유연한 행동 정책(Action Policy)을 생성하는 기반이 됩니다.
이러한 멀티모달 시너지 효과는 CLIPort와 VIMA 같은 초기 연구들을 통해 그 가능성을 입증했으며, 최근에는 더욱 발전된 형태로 나타나고 있습니다. VoxPoser는 3D 공간에서의 모호성을 해결하고, RT-2는 처음 보는 명령에도 대응할 수 있는 제로샷 일반화 능력을 보여주었습니다. 또한 Octo와 같은 모델은 메모리 기능을 추가하여 장기적인 의사결정 능력을 확장했으며, Occllama는 가려진 객체를 추론하는 등 현실 세계의 복잡한 문제들을 해결하고 있습니다.
결론적으로, VLA의 통합은 단순히 데이터를 합치는 표면적인 융합을 넘어, 여러 정보에 걸쳐 의미론적, 공간적, 시간적 관계를 깊이 있게 이해하고 정렬하는 것을 의미합니다. 이 덕분에 VLA 모델은 과거에는 불가능했던 수준의 유연하고 지능적인 행동을 수행할 수 있게 되었습니다.
2.3. Tokenization and Representation: How VLAs Encode the World
VLA 모델을 기존의 시각-언어 아키텍처와 구별 짓는 핵심 혁신은 모든 정보를 ‘토큰(token)’이라는 이산적인 단위로 변환하여 처리하는 표현 프레임워크에 있습니다. 자연어 생성 모델에서 영감을 받은 이 접근법은 시각적 인식, 언어적 지시, 그리고 로봇의 물리적 상태와 행동까지 모두 하나의 공유된 임베딩 공간으로 통합합니다. 이를 통해 모델은 단순히 “무엇을 해야 하는지”를 의미적으로 이해할 뿐만 아니라, “어떻게 해야 하는지”에 대한 구체적인 제어 정책까지 하나의 학습 가능한 방식으로 추론할 수 있게 됩니다.
이러한 프레임워크는 크게 세 가지 종류의 토큰으로 구성됩니다.
1. 접두사 토큰 (Prefix Tokens): 컨텍스트 및 명령 인코딩
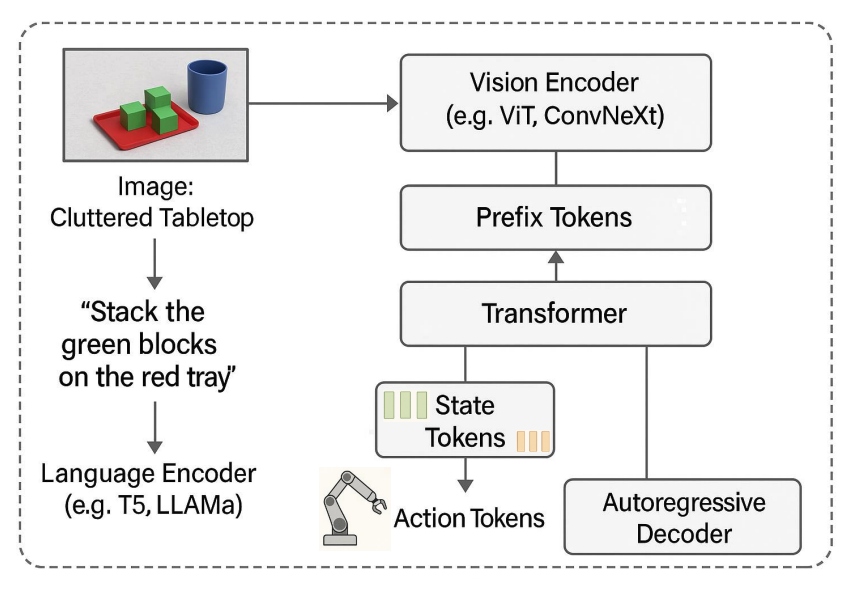
- 역할: 모델의 컨텍스트 백본(contextual backbone) 역할
- 정보: 환경 정보(이미지, 비디오)와 자연어 명령을 압축된 임베딩으로 인코딩.
- 작동 방식 (Figure 7 참조):
- 비전 인코더 (ViT 등): 장면 이미지를 처리.
- 언어 모델 (T5 등): “녹색 블록을 빨간색 트레이에 쌓아라”와 같은 명령어를 임베딩.
- 두 정보가 접두사 토큰 시퀀스로 변환되어 모델의 목표와 환경에 대한 초기 이해를 형성.
- 기능: 서로 다른 정보(시각, 언어)를 연결(grounding)하여 “파란색 컵 옆의 녹색 블록”과 같은 공간적, 의미적 관계를 이해하게 함.
2. 상태 토큰 (State Tokens): 로봇의 물리적 상태 임베딩
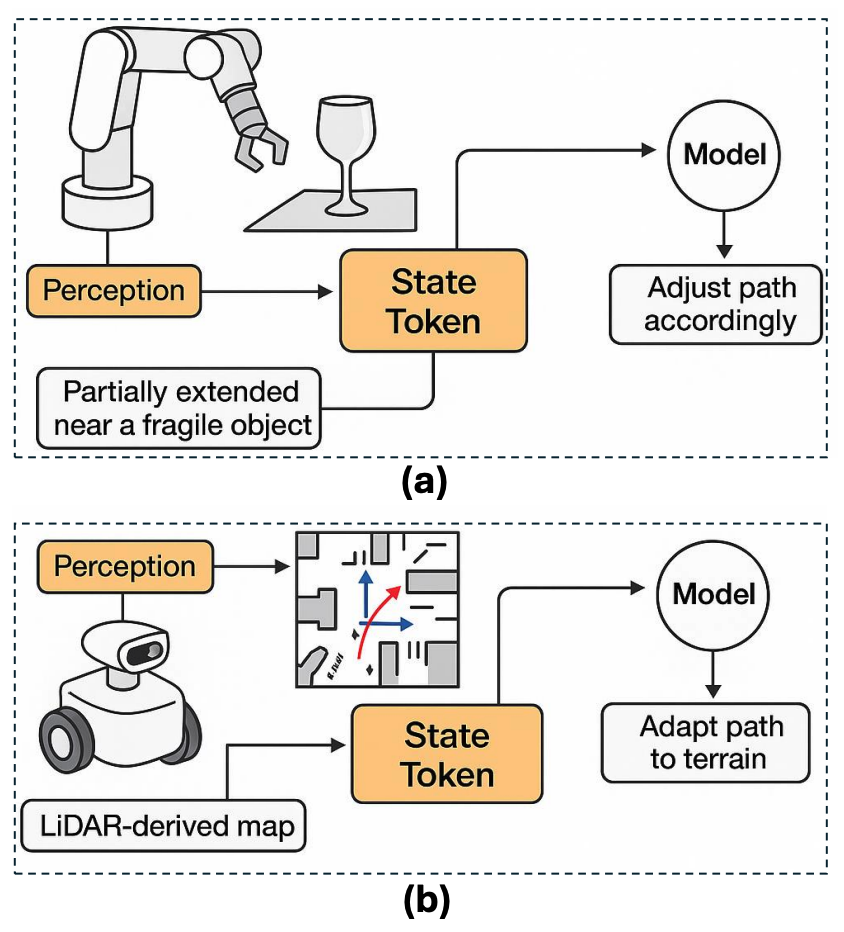
- 역할: 로봇의 내부 물리적 상태를 실시간으로 인코딩.
- 정보: 관절 각도, end-effector 자세, 그리퍼 상태, 힘-토크 센서 값 등 고유수용성(proprioceptive) 정보를 포함.
- 중요성 (Figure 8 참조):
- 조작 시: 로봇 팔이 물체에 충돌할 위험이 있을 때, 상태 토큰이 현재 관절 각도, 그리퍼 위치 등의 정보를 제공. 모델은 이를 바탕으로 충돌을 예측하고 궤도를 수정하거나 힘을 조절함.
- 이동 시: 모바일 로봇의 주행 거리, LiDAR 스캔 데이터 등을 캡슐화하여 지형을 인지하고 장애물을 회피하는 데 필수적임.
- 기능: 외부 환경 정보(접두사 토큰)와 내부 상태 정보(상태 토큰)를 융합하여, 상황을 정확히 인식하고 안전하고 정밀한 의사결정을 가능하게 함.
3. 액션 토큰 (Action Tokens): 자기회귀적 제어 생성
- 역할: 모델이 생성하는 최종 출력으로, 로봇의 다음 행동 단계를 나타냄
- 정보: 관절 각도 업데이트, 휠 속도, 그리퍼 힘 조절 등 저수준 제어 신호나 “잡기 자세로 이동” 같은 고수준 행동 명령에 해당
- 생성 방식:
- 접두사 토큰과 상태 토큰을 조건으로, 자기회귀 방식(auto-regressively)으로 다음 액션 토큰을 한 단계씩 예측함 (언어 모델이 다음 단어를 예측하는 것과 유사)
- 장점 (Figure 9 참조):
- 물리적 행동 시퀀스 생성을 자연어 생성 문제처럼 다룰 수 있음.
- 실제 로봇 제어 시스템과 원활하게 통합되며, 가변 길이의 행동 시퀀스를 지원.
- 강화 학습이나 모방 학습을 통해 파인 튜닝이 용이함.
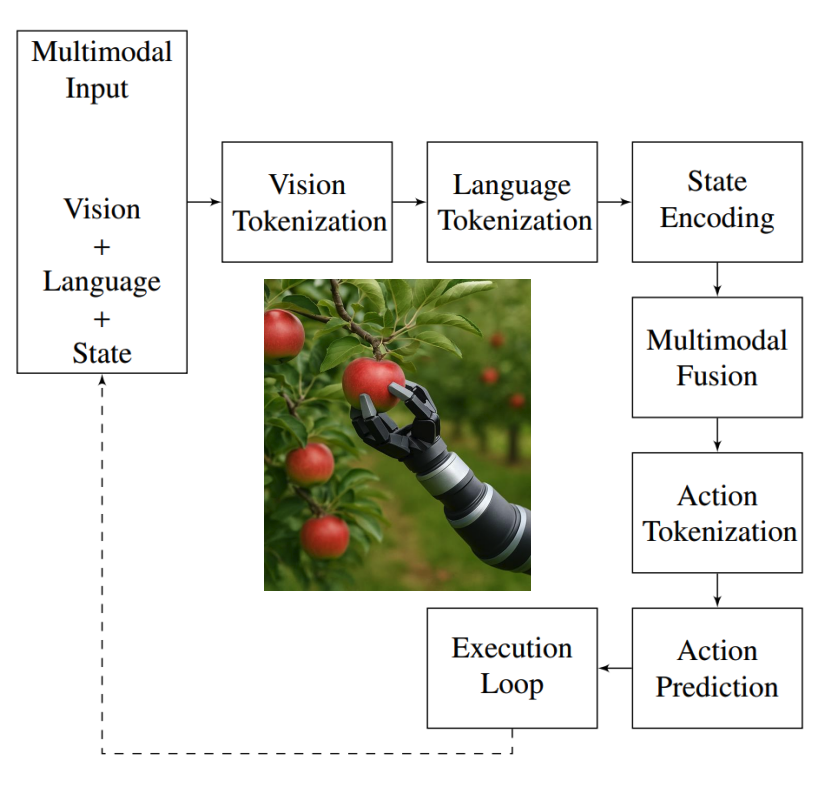
로봇 공학에서 VLA 패러다임을 작동시키기 위해 Figure 9에서 멀티모달 정보(특히 시각, 언어 및 고유 수용성 상태)가 인코딩, 융합되고 실행 가능한 동작 시퀀스로 변환되는 방식을 보여주는 구조화된 파이프라인을 제시합니다
전체 파이프라인 요약 (Figure 9 및 Algorithm 1 참조)
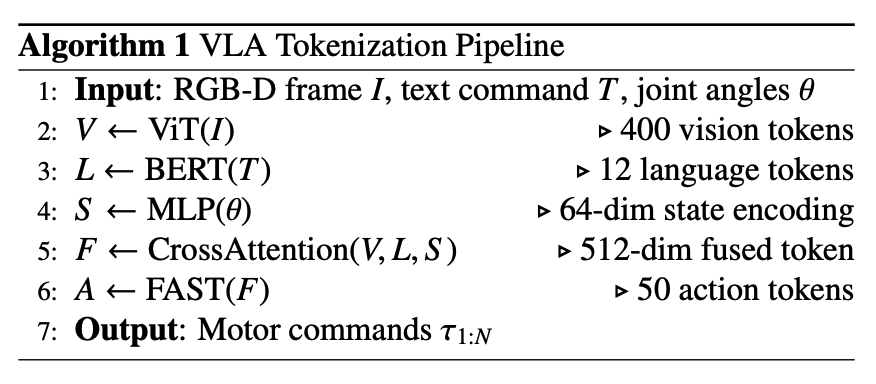
- 입력 획득: RGB-D 이미지, 자연어 명령, 로봇 상태(관절 각도 등) 데이터를 수집
- 개별 토큰화:
- 이미지 → 비전 토큰 (by ViT)
- 명령어 → 언어 토큰 (by BERT/T5)
- 로봇 상태 → 상태 토큰 (by MLP)
- 멀티모달 융합: 개별 토큰들을 Cross-Modal Attention 메커니즘으로 융합하여 의미, 의도, 상황 인식을 모두 담은 통합 표현(fused representation)을 생성
- 액션 토큰 생성: 융합된 표현을 autoregressive decoder(일반적으로 Transformer)에 입력하여, 일련의 액션 토큰을 순차적으로 예측
- 실행 및 피드백: 생성된 액션 토큰을 실제 모터 명령으로 변환하여 로봇이 실행. 실행 후 업데이트된 로봇 상태는 다시 입력으로 피드백되어 다음 추론 단계를 위한 폐쇄 루프(closed-loop)를 형성함으로써, 실시간으로 변화하는 환경에 동적으로 적응할 수 있게 만듦
이처럼 VLA의 토큰 기반 프레임워크는 서로 다른 종류의 정보를 일관된 공간에서 통합하고, 이를 통해 지능적이고 유연한 행동을 생성하는 강력한 메커니즘을 제공합니다.
2.4. Learning Paradigms: Data Sources and Training Strategies
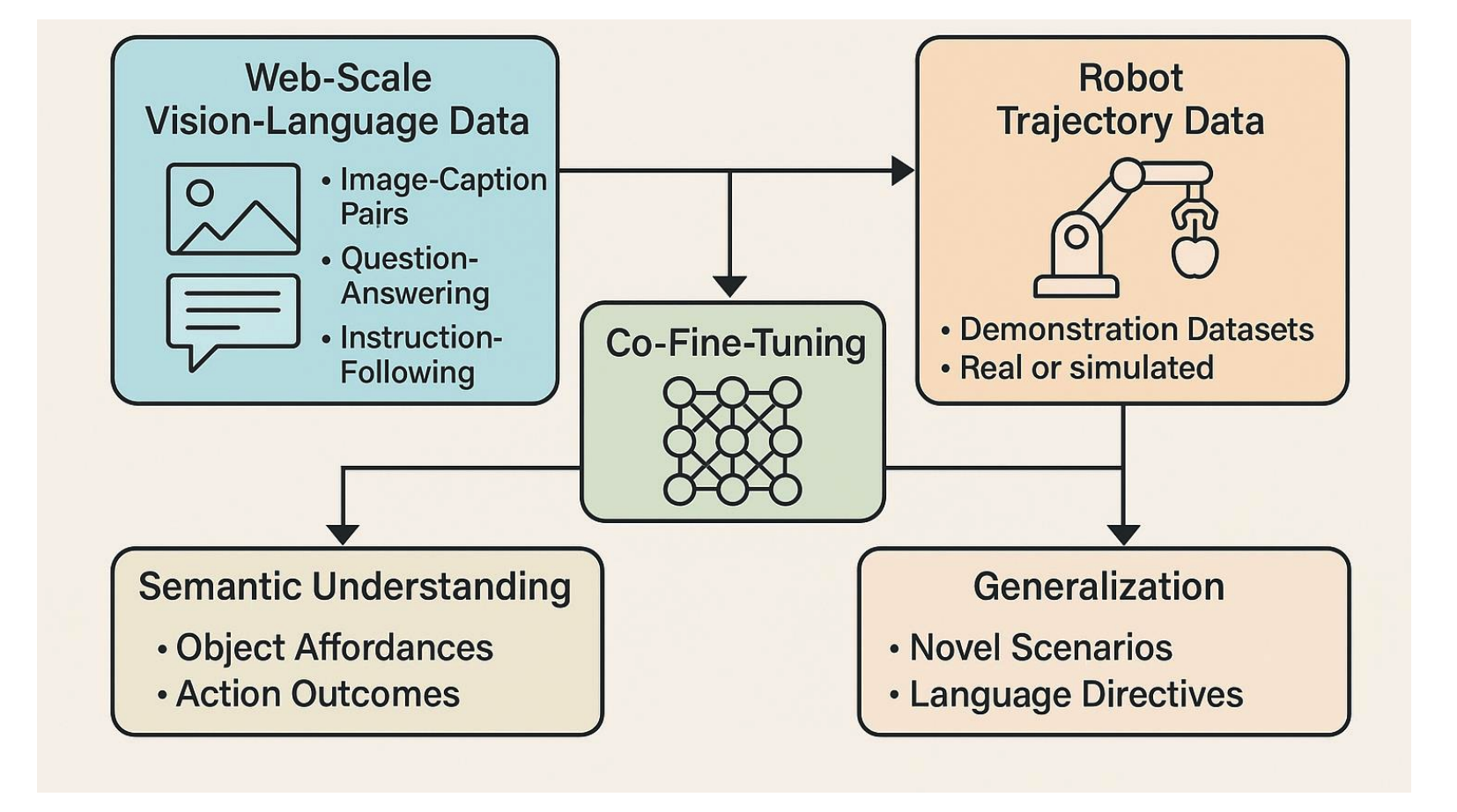
VLA 모델을 훈련시키기 위해서는 웹에서 얻은 방대한 의미론적 지식과 로봇 데이터셋의 실제 작업 정보를 결합하는 하이브리드 학습 패러다임이 필수적입니다. 이 과정은 일반적으로 두 단계로 진행됩니다. 첫 번째 사전 훈련 단계에서는 이미지-캡션 쌍과 같은 대규모 인터넷 데이터를 사용하여 모델에 세상에 대한 범용적인 이해와 상식 추론 능력을 주입합니다. 이 단계는 모델이 객체, 행동, 개념에 대한 기본적인 표현을 학습하고 시각과 언어 정보를 하나의 공유된 공간에서 정렬하도록 만들어, 이후 새로운 작업을 수행할 수 있는 기반을 마련합니다.
그러나 의미론적 이해만으로는 물리적인 작업을 실행할 수 없으므로, 두 번째 파인 튜닝 단계가 필요합니다. 이 단계에서는 실제 로봇이나 시뮬레이터에서 수집된 궤적 데이터를 사용하여, 사전 훈련으로 얻은 지식을 구체적인 물리적 행동으로 연결하는 방법을 학습시킵니다. 모델은 전문가의 시연을 모방하거나(행동 복제), 보상을 통해 최적의 행동을 찾아가는 방식(강화 학습)으로, 주어진 상황과 명령에 맞는 다음 액션 토큰을 예측하도록 훈련됩니다.
더 나아가, 최근 연구에서는 웹 데이터와 로봇 데이터를 함께 사용하여 의미와 행동의 정렬을 강화하는 Co-fine-tuning, 쉬운 작업부터 복잡한 작업 순으로 학습 효율을 높이는 커리큘럼 학습(Curriculum Learning), 그리고 시뮬레이션과 현실 간의 격차를 해소하는 도메인 적응(Sim-to-real)과 같은 더욱 정교한 전략들이 활발히 도입되고 있습니다.
이러한 접근법의 대표적인 사례인 Google의 RT-2는 웹 데이터와 로봇 데모 데이터를 모두 활용할 뿐만 아니라, 로봇의 행동 생성을 마치 텍스트를 생성하는 문제처럼 다루어, 처음 보는 명령이나 객체에 대해서도 뛰어난 제로샷(zero-shot) 일반화 능력을 보여주며 VLA 패러다임의 무한한 잠재력을 입증했습니다.
2.5. Adaptive Control and Real-Time Execution
VLA는 센서로부터 들어오는 실시간 피드백을 사용하여 즉석에서 행동을 동적으로 조정(adaptive control)할 수 있습니다. 예를 들어, 로봇이 사과를 따는 도중 바람에 사과가 흔들리거나 다른 물체가 시야를 가리면, 모델은 실시간으로 업데이트되는 상태 토큰을 통해 이 변화를 인지하고 즉시 로봇 팔의 궤적을 수정합니다. 이처럼 예측 불가능한 변화가 빈번한 실제 환경에 유연하게 대처하는 능력은 인간과 유사한 적응성을 보여주는 것으로, 정해진 시나리오대로만 움직이는 기존 파이프라인 기반 로봇 시스템과 VLA를 구분 짓는 결정적인 장점입니다.
3. Progress in Vision-Language-Action Models
VLA 모델의 등장은 ChatGPT와 같은 LLM의 경이로운 성공에 크게 힘입었습니다. LLM이 보여준 뛰어난 추론 능력은 연구자들이 언어 모델의 힘을 로봇 공학의 인식 및 행동 영역으로 확장하도록 영감을 주었으며, 이후 이미지까지 처리하는 GPT-4의 등장은 이러한 흐름을 더욱 가속화했습니다. 여기에 더해, CLIP 및 Flamingo과 같은 VLM이 시각과 텍스트 정보를 정렬하는 기술적 토대를 마련했고, RT-1과 같은 대규모 로봇 데이터셋이 실제 행동 데이터를 제공함으로써 VLA 모델 발전을 위한 모든 준비가 갖추어졌습니다.
이러한 배경 속에서 Google의 RT-2는 비전, 언어, 행동 토큰을 통합하여 로봇 제어를 언어 모델처럼 자기회귀 시퀀스 예측 문제로 정의하며 VLA 아키텍처의 획기적인 전환을 이끌었고, UC Berkeley의 Octo는 대규모 로봇 데모(OpenX-Embodiment 데이터셋)로 훈련된 오픈 소스 모델을 공개하며 연구 커뮤니티의 발전을 촉진했습니다. 최근에는 훈련 패러다임 또한 웹 데이터와 로봇 데이터를 함께 파인 튜닝하거나, \(\pi_0\) 모델과 같이 합성 데이터를 활용하고, LoRA와 같은 효율적인 훈련 기법을 도입하는 등 빠르게 진화하고 있습니다.
3.1. Architectural Innovations in VLA Models
이러한 발전을 거치며 VLA 모델의 아키텍처는 최근 세 가지 주요 패러다임으로 수렴하는 경향을 보입니다.
1. 초기 융합 모델 (Early-Fusion Models)
- 개념: 입력 단계에서 비전과 언어 표현을 먼저 융합한 후, 정책 모듈로 전달
- 사례: EF-VLA (2025): CLIP의 고정된 인코더를 사용하여 의미론적 일관성을 유지
- 장점: 과적합 감소, 일반화 성능 향상, 계산 효율성 유지, 치명적 망각(catastrophic forgetting) 방지
2. 이중 시스템 아키텍처 (Dual-System Architectures)
- 개념: 인간 인지의 이중 처리 이론에서 영감을 받아, 두 개의 상호 보완적인 시스템을 구현
- System 1 (빠른 반응 모듈): 저지연(10ms) 확산 정책을 통해 저수준 실시간 제어 담당 (ex. end-effector 안정화 또는 적응형 파지(adaptive grasping))
- System 2 (느린 추론 플래너): LLM 기반 플래너를 통해 고수준 작업 계획을 원자적 하위 작업으로 구문 분석 (ex. 테이블 청소)
- 사례: Groot N1 (NVIDIA, 2025)
- 장점: 다중 시간 척도 추론 가능, 안전성 향상, 복잡한 작업 수행 능력 증대
3. 자기 수정 프레임워크 (Self-Correcting Frameworks)
- 개념: 외부 감독 없이 스스로 실패를 감지하고 복구하는 능력
- 사례: SC-VLA (2024):
- 빠른 추론 경로: 기본 행동을 신속하게 생성
- 느린 수정 경로: 실패 감지 시, LLM을 활용한 연쇄적 사고(Chain-of-Thought) 추론으로 실패 원인을 진단하고 수정 전략을 생성 (ex. 활성 시점 변경 또는 그리퍼 재정렬 제안)
- 장점: 작업 실패율 감소, 복잡하고 예측 불가능한 환경에서의 견고성(robustness) 향상
이처럼 VLA 모델들은 end-to-end 통합과 모듈식 분리, 계층적 계획과 평면적 제어 등 다양한 설계 철학 사이에서 균형을 맞추며 발전하고 있습니다. 본 논문에서는 이러한 모델들을 체계적으로 분류하고 비교하여 각 아키텍처의 강점과 한계를 명확히 하고, 이를 통해 미래 연구자들이 특정 응용 분야에 가장 적합한 모델을 설계하고 VLA 기술의 발전을 가속화하는 데 기여하고자 합니다.
또한 VLA 모델의 최근 발전을 종합하기 위해 Table 2는 2022년부터 2025년까지 개발된 주목할만한 시스템의 비교 요약을 제시합니다.

3.2. Training and Efficiency Advancements in Vision–Language–Action Models
VLA 모델은 컴퓨팅 요구 사항을 줄이고 실시간 제어를 가능하게 하는 방향으로 훈련 및 최적화 기술이 빠르게 발전하고 있음. 주요 발전 영역은 아래와 같음.
- 데이터 효율적 학습 (Data-Efficient Learning)
- 목표: 더 적은 데이터로 더 나은 성능을 달성하고, 데이터 부족 문제를 해결
- 주요 기술:
- Co-fine-tuning (공동 파인 튜닝):
- 방법: 웹 데이터(LAION-5B 등)와 로봇 데이터(Open X-Embodiment 등)를 함께 사용하여 파인 튜닝
- 효과: 의미 이해(semantic)와 운동 기술(motor skill)을 효과적으로 정렬
- 사례: OpenVLA(7B)는 더 큰 모델인 RT-2(55B)보다 16.5% 더 높은 성공률을 달성하며, 적은 파라미터로도 강력한 일반화가 가능함을 입증
- Synthetic Data Generation (합성 데이터 생성):
- 방법: UniSim과 같은 도구를 사용하여 가려짐(occlusion), 동적 조명(dynamic lighting) 등 현실적인 시나리오를 인공적으로 생성
- 효과: 실제 데이터로 얻기 힘든 희귀한 edge-case를 보강하여, 복잡한 환경에서 모델의 견고성(robustness)을 20% 이상 향상
- Self-Supervised Pretraining (자가 지도 사전 학습):
- 방법: CLIP처럼 대조 학습(contrastive objectives)을 사용하여, 레이블 없는 데이터로 시각-텍스트 임베딩을 사전 학습
- 효과: 특정 작업 레이블에 대한 의존도를 줄이고, 이후 액션 파인 튜닝 단계의 수렴 속도를 가속화
- 사례: Qwen2-VL은 이 방식을 활용하여 물체 잡기 작업의 수렴 속도를 12% 가속화
- 파라미터 효율적 적응 (Parameter-Efficient Adaptation)
- 목표: 거대한 모델 전체를 훈련하지 않고, 일부만 수정하여 효율적으로 적응
- 주요 기술:
- LoRA (Low-Rank Adaptation):
- 방법: 사전 훈련된 거대 모델의 가중치는 고정(freeze)하고, 가벼운 어댑터(adapter) 행렬만 추가하여 학습
- 효과: 성능을 유지하면서 훈련해야 할 가중치를 최대 70%까지 줄임
- 사례: \(\pi_0\)-Fast 모델은 단 10M개의 어댑터 파라미터만 사용하여, 거의 성능 저하 없이 200Hz의 연속 제어를 달성
- 추론 가속화 (Inference Acceleration)
- 목표: 모델의 실행 속도를 높여 실시간 제어를 가능하게 함
- 주요 기술:
- Compressed Action Tokens & Parallel Decoding:
- 방법: 액션 토큰을 압축하고, 병렬 디코딩 기술을 사용.
- 효과: 궤적의 부드러움은 약간 손해 보지만, 5ms 미만의 초저지연을 달성하고 정책 실행 속도를 2.5배 향상
- 사례: Groot N1과 같은 이중 시스템 프레임워크에서 사용
- Hardware-Aware Optimizations (하드웨어 최적화):
- 방법: 텐서 코어 양자화(quantization), 파이프라인 어텐션 커널 등 하드웨어 특성에 맞춰 모델을 최적화
- 효과: 런타임 메모리 사용량을 8GB 미만으로 줄여, 임베디드 GPU에서도 실시간 추론이 가능하게 함
이러한 다각적인 효율성 향상 기술들은 VLA 모델을 이론적인 개념에서 벗어나, 동적인 실제 환경에서 언어 기반의 시각 유도 작업을 처리할 수 있는 실용적인 에이전트로 변모시켰음.
3.3. Parameter-Efficient Methods and Acceleration Techniques in VLA Models
리소스가 제한된 로봇 플랫폼에 VLA 모델을 배포하기 위해, 모델의 크기를 줄이고(파라미터 효율성) 추론 속도를 높이는(가속) 기술들이 중요해짐.
- LoRA (Low-Rank Adaptation)
- 방법: 거대한 사전 훈련 모델의 가중치는 고정하고, 작은 훈련 가능한 행렬(어댑터)만 추가하여 파인 튜닝
- 효과:
- GPU 컴퓨팅 자원을 70% 절약하면서 수십억 파라미터 모델을 튜닝 가능
- 소규모 연구실에서도 소비자용 GPU로 대규모 VLA 모델을 활용할 수 있게 됨
- 사례: OpenVLA는 20M 파라미터의 LoRA 어댑터만으로 7B 모델을 24시간 내에 튜닝
- Quantization (양자화)
- 방법: 모델 가중치의 정밀도를 Float32에서 INT8로 낮춤
- 효과: 모델 크기는 절반으로, 처리량은 두 배로 증가
- 사례: Jetson Orin에서 INT8 양자화를 적용한 OpenVLA는 성능 저하를 최소화(5% 이내)하면서 50W급 엣지 장치에서 30Hz 제어를 가능하게 함
- Model Pruning (모델 가지치기)
- 방법: 불필요하다고 판단되는 모델의 일부(어텐션 헤드 등)를 제거
- 효과: 메모리 사용량을 25% 줄여 4GB 미만의 저사양 환경에서도 배포 가능
- 사례: Diffusion Policy의 비전 인코더 20%를 가지치기해도 성능 저하는 미미했음
- Compressed Action Tokenization (FAST)
- 방법: 연속적인 액션 출력을 주파수 영역의 토큰으로 변환하여, 긴 제어 시퀀스를 짧게 압축
- 효과: 추론 속도를 15배 향상시켜 200Hz의 초고속 정책 실행이 가능
- 사례: \(\pi_0\)-Fast 모델은 이 기술로 양손 조립과 같은 동적인 작업에 적합한 고주파 제어를 달성
- Parallel Decoding and Action Chunking (병렬 디코딩 및 액션 청킹)
- 방법:
- 병렬 디코딩: 액션 토큰을 하나씩 순차적으로 생성하는 대신, 여러 토큰 그룹을 동시에 디코딩
- 액션 청킹: “컵 들고 놓기”와 같은 다단계 행동을 하나의 토큰으로 추상화
- 효과: Groot N1은 순차적 디코딩의 병목 현상을 해결하여, 지연 시간을 2.5배 단축하고 추론 단계를 40%까지 줄임. 100~200Hz의 빠른 결정 속도를 지원.
- 방법:
- Reinforcement Learning–Supervised Hybrid Training (RL-SL 하이브리드 훈련)
- 방법:
- 강화 학습(RL)과 인간 시연 데이터 기반의 지도 학습(SL)을 번갈아 가며 훈련
- Direct Preference Optimization (DPO)을 활용하여 보상 모델을 형성하고 Conservative QLearning을 사용하여 외삽 오류를 방지
- 효과:
- RL의 불안정한 탐색 문제를 안정화하고, SL의 의미 충실도를 유지
- 순수 RL 대비 샘플 복잡성을 60% 줄이면서, 동적 장애물 회피와 같은 어려운 작업에 대한 강력한 정책을 학습
- 사례: iRe-VLA 프레임워크
- 방법:
- Hardware-Aware Optimizations (하드웨어 최적화)
- 방법: NVIDIA TensorRT-LLM과 같은 컴파일러를 사용하여, 타겟 하드웨어의 기능(ex. 텐서 코어, fused attention 등)을 최대한 활용하도록 모델 그래프와 커널을 최적화
- 효과: OpenVLA-OFT는 추론 지연 시간을 30%, 에너지 소비를 25% 감소시켜 모바일 로봇이나 드론과 같은 전력 제한적인 환경에서도 실시간 VLA 구동을 가능하게 함
이러한 파라미터 효율화 및 가속 기술들은 VLA 모델 배포를 대중화(democratize)하는 데 결정적인 역할을 한다. 이를 통해 VLA는 더 이상 연구실의 프로토타입에 머무르지 않고, 산업용 매니퓰레이터, 보조 드론, 소비자 로봇 등 실제 자율 시스템에 내장될 수 있는 실용적인 기술로 거듭나고 있다.
3.4. Applications of Vision-Language-Action Models
VLA 모델은 지각, 자연어 이해, 모터 제어를 하나의 아키텍처로 통합함으로써, 로봇과 같은 구체화된 지능(Embodied Intelligence)을 위한 핵심 구성 요소로 빠르게 자리 잡고 있습니다. 시각 정보와 언어적 지시를 공유된 의미 공간으로 인코딩하고, 이를 바탕으로 상황에 맞는 행동을 생성하는 VLA의 능력은 휴머노이드 로보틱스부터 자율 주행, 산업 자동화, 농업에 이르기까지 광범위한 실제 응용 분야에서 혁신을 주도하고 있습니다.
부록의 Table 3은 방법론, 응용 분야 및 주요 혁신을 요약하여 최근 VLA 모델을 보여줍니다.
3.4.1. Humanoid Robotics

VLA 모델은 인간의 형태와 기능을 모방하는 휴머노이드 로봇 분야에 혁신을 가져오고 있습니다. 이러한 혁신의 핵심에는 기존의 분리된 모듈 방식에서 벗어난 통합 토큰 기반 프레임워크가 있습니다. 이 아키텍처는 시각 정보(DINOv2, SigLIP 등)와 언어 명령(Llama-2, GPT 등)을 각각 토큰으로 변환하고, 이를 융합하여 상황을 종합적으로 이해한 뒤, 로봇의 움직임을 나타내는 행동 토큰을 순차적으로 생성합니다.
Figure AI가 개발한 ‘Helix’ 는 이러한 아키텍처의 대표적인 사례로, 완전 통합된 VLA 모델을 통해 전신을 실시간으로 제어합니다. 특히 멀티모달 트랜스포머가 고수준의 계획을 세우고, 실시간 모터 정책이 200Hz의 고주파로 정밀한 동작을 실행하는 이중 시스템을 통해, 처음 보는 물체나 작업에도 별도의 재학습 없이 유연하게 적응하는 능력을 보여줍니다.
이러한 기술은 TinyVLA, MoManipVLA와 같은 경량화 모델의 등장으로 실제 환경 배포가 가속화되고 있습니다. 이 모델들은 저전력 GPU에서도 고성능을 유지하여 로봇의 이동성과 실용성을 크게 높였습니다. 이를 바탕으로 VLA 기반 휴머노이드 로봇은 가정 내 가사 노동, 의료 현장에서의 수술 보조(RoboNurse-VLA), 그리고 물류 창고의 반복 작업 수행 등 다양한 분야로 영향력을 확장하고 있습니다.
궁극적으로 VLA 모델은 휴머노이드 로봇을 ‘신뢰할 수 있는 제너럴리스트 협력자’ 로 전환시키는 것을 목표로 합니다. 예를 들어 ‘Helix’는 “냉장고에서 물병을 가져와 줘”라는 명령에 대해, 상황 인식, 하위 작업 계획, 정밀 제어, 그리고 돌발 상황에 대한 실시간 적응까지 계층적으로 수행합니다.
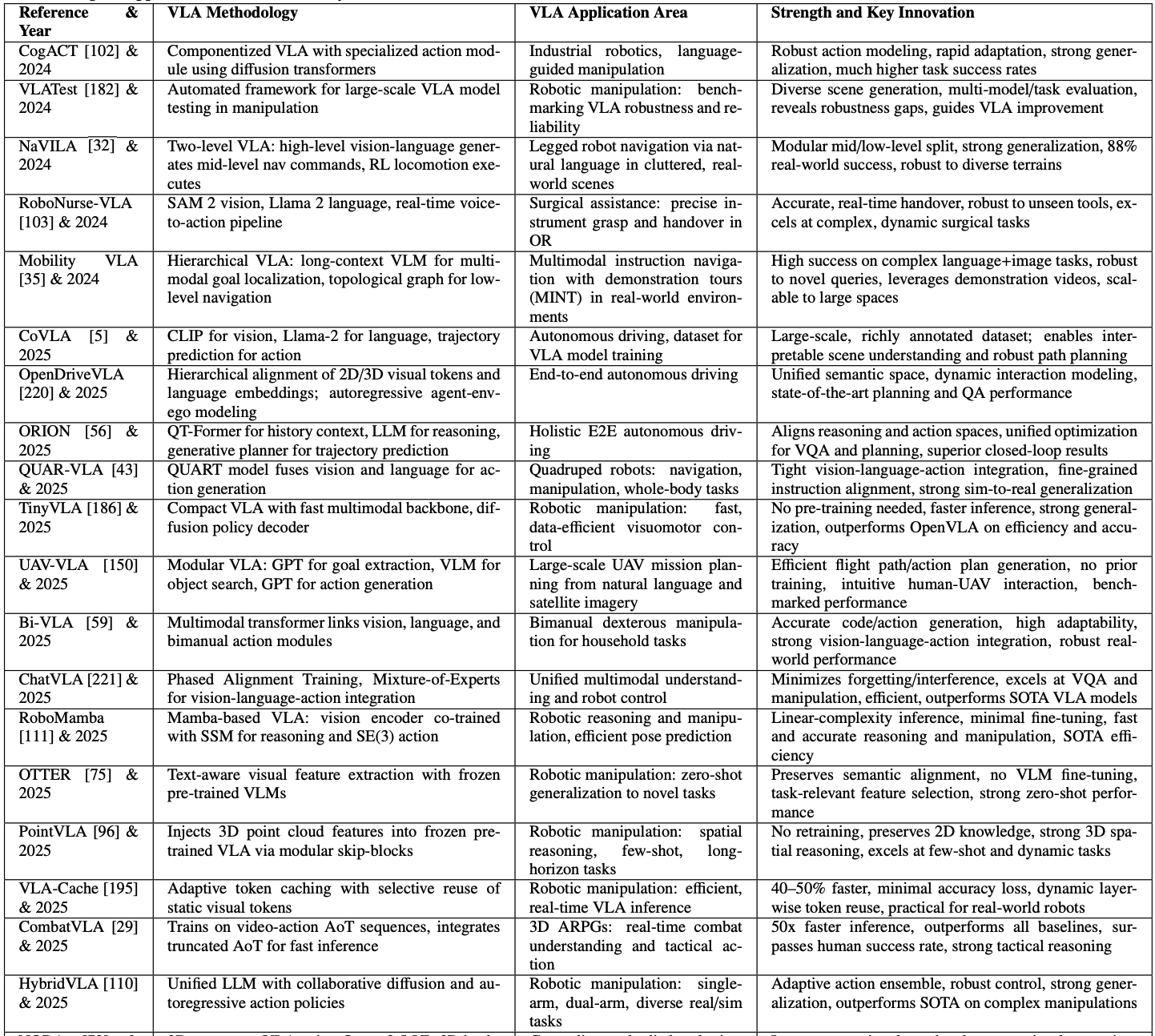
3.4.2. Autonomous Vehicle Systems
자율 주행 시스템에서 VLA 모델은 기존의 ‘인식-계획-제어’가 분리된 모듈식 접근법과 달리, 시각 정보, 자연어 지시, 각종 센서 데이터를 하나의 통합된 프레임워크 내에서 처리하여 정밀한 운전 행동을 직접 생성합니다. 이를 통해 자율주행차는 단순히 객체를 인식하는 것을 넘어, “빨간 트럭 다음 출구로 나가세요”와 같은 복잡한 언어적, 상황적 맥락을 이해하고 그에 맞는 주행을 할 수 있게 됩니다.
이러한 발전을 이끈 대표적인 모델로는 대규모 데이터셋을 구축한 CoVLA, 2D/3D 시각 정보를 언어와 통합하여 해석 가능한 궤적을 생성하는 OpenDriveVLA, 그리고 장거리 시각 정보를 활용해 모호한 상황 판단에 강점을 보이는 ORION 등이 있습니다. 이 모델들은 VLM과 LLM을 결합하여 인간 수준의 의미 이해와 로봇의 물리적 제어를 효과적으로 연결합니다.
가령, 자율 배달 차량이 “빵집 옆에 소포를 두고 공사 구역을 피해 복귀하라”는 복합적인 명령을 받았을 때, VLA 시스템은 실시간으로 주변 랜드마크를 식별하고, 센서 데이터와 융합하여 최적의 경로를 계획합니다. 만약 예상치 못한 보행자가 나타나면 즉시 궤도를 수정하고 속도를 조절하는 등 안전 중심의 실시간 적응 능력을 보여줍니다. 이러한 기술은 지상 차량뿐만 아니라, 고수준의 임무를 수행하는 배달 드론이나 UAV와 같은 항공 로봇 공학에도 적용되어 그 활용 범위를 넓히고 있습니다.
3.4.3. Industrial Robotics
산업 로봇 공학 분야는 VLA 모델의 도입으로 시각 정보와 자연어 명령을 결합해 상황을 스스로 추론하고 실시간으로 적응하는 지능형 로봇의 등장을 가능하게 했습니다.
이러한 혁신의 중심에는 산업용 조작을 위해 특별히 설계된 CogACT와 같은 VLA 프레임워크가 있습니다. CogACT는 기존 모델과 달리 diffusion-based action transformer(DiT)를 도입하여, 더욱 강건하고 정밀한 모터 제어 시퀀스를 생성합니다. 또한, 모듈식 설계를 통해 다양한 형태의 로봇에 빠르게 파인 튜닝하여 적용할 수 있는 높은 범용성을 자랑합니다. 실제 실험에서 CogACT는 복잡한 조립 및 분류 작업에서 기존 모델보다 59% 이상 높은 성공률을 기록하며 그 우수성을 입증했습니다.
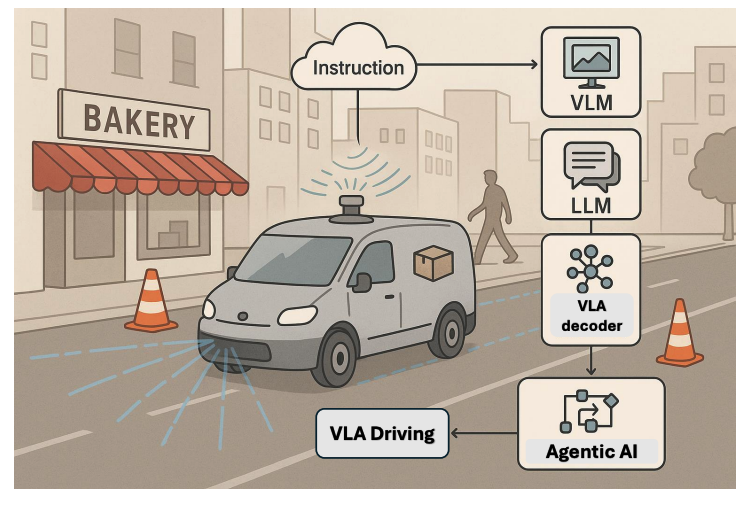
3.4.4. Healthcare and Medical Robotics
수술 로봇 분야에서 VLA는 최소 침습 수술(minimally invasive operations)의 기능을 극대화합니다. 로봇은 복강경 영상과 외과의의 음성 명령(“왼쪽 관상 동맥에 봉합사 적용”)을 동시에 이해하고, 이를 서브밀리미터 단위의 정밀한 모션으로 변환하여 실행합니다. 이를 통해 도구를 자율적으로 재배치하거나 중요 조직을 회피함으로써 외과의의 부담과 인적 오류를 크게 줄일 수 있습니다.
수술실 밖에서는 환자 지원 로봇에 VLA 기술이 적용됩니다. 예를 들어, 로봇은 환자의 움직임과 음성 요청(“내 보행기 가져와”)을 인식하고, 상황에 맞는 보조 행동을 자율적으로 수행합니다. RoboNurse-VLA와 같은 실제 프레임워크는 수술 기구 전달과 같은 작업을 성공적으로 수행하며, 다양한 환경 변화에 대한 강건성을 입증했습니다.
3.4.5. Precision and Automated Agriculture
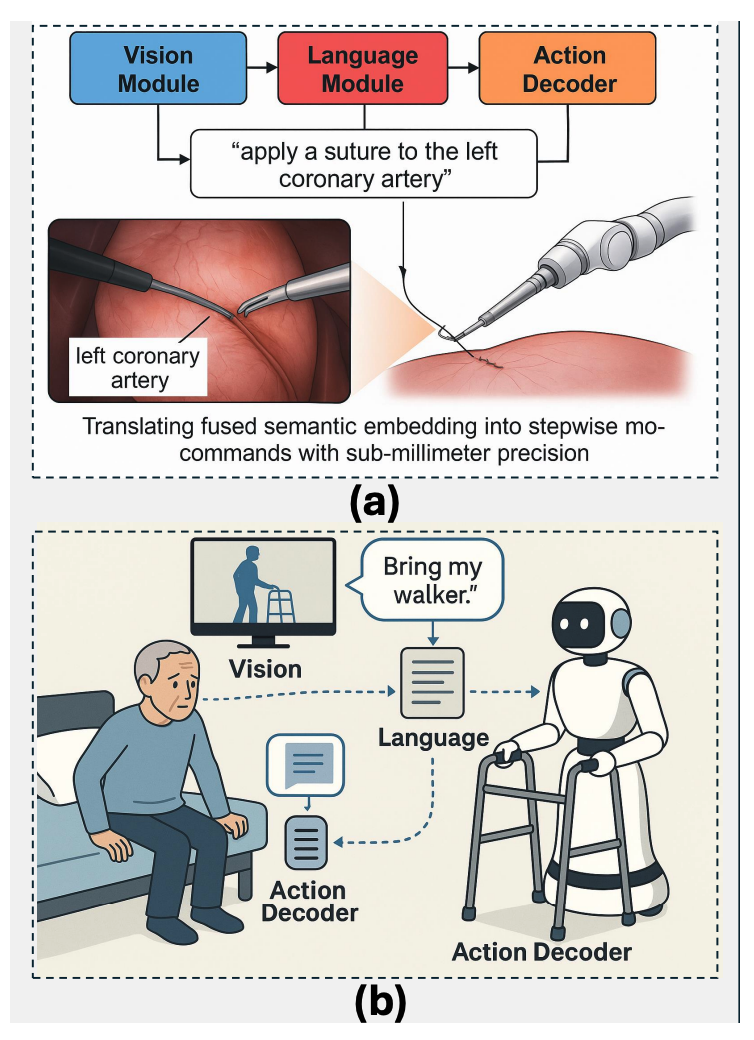
VLA 모델은 정밀 및 자동화 농업 분야에서 가려진 작물을 인식하고, 불규칙한 지형을 탐색하며, 다양한 작물 유형에 유연하게 대응할 수 있습니다.
작동 방식은 Vision Transformers와 LLM을 핵심으로 합니다. 예를 들어, 과일 수확 로봇은 카메라로 농산물의 숙성도를 파악하고, “A급 과일만 수확하라”는 농부의 언어 지시를 이해하여 정밀한 수확 작업을 자율적으로 수행합니다. 또한, 드론은 지시를 받아 특정 구역의 질병을 탐지하거나 필요한 곳에만 물을 공급하는 등 정밀한 관리가 가능해져 물 사용량을 최대 30%까지 절감할 수 있습니다.
VLA의 지속적인 학습과 뛰어난 일반화 능력으로, 실제 같은 3D 시뮬레이션 환경에서 생성된 합성 데이터로 훈련하여 다양한 병충해나 작물 상태를 학습하고, LoRA와 같은 기술을 통해 새로운 작물이나 지역에도 빠르게 적응할 수 있습니다.
3.4.6. Interactive AR Navigation with Vision-Language-Action Models
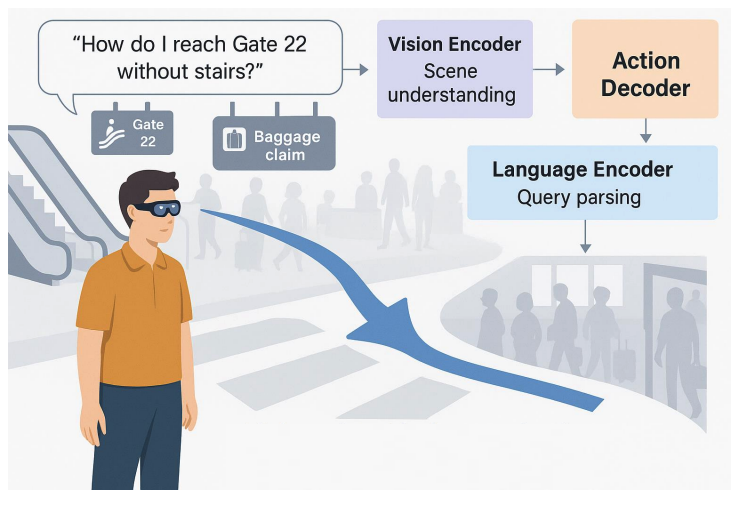
VLA 모델은 대화형 증강현실(AR) 내비게이션 분야에서 인간과 환경의 상호작용을 혁신하고 있습니다. 기존 GPS 시스템이 고정된 지도에 의존했던 것과 달리, VLA 기반 AR 에이전트는 스마트 기기의 카메라로 들어오는 실시간 시각 정보와 사용자의 자연어 질문을 동시에 이해하여, 물리적 세계 위에 직접 동적인 길 안내 정보를 증강현실로 보여줍니다.
이 시스템의 핵심은 비전 인코더가 복잡한 장면을 해석하고, 언어 인코더가 사용자의 의도(“휠체어 경사로가 있는 가장 가까운 약국으로 가줘”)를 파악한 뒤, 이 둘을 융합하여 방향 화살표나 웨이포인트 같은 내비게이션 신호를 실시간으로 생성하는 것입니다. 예를 들어, 공항에서 사용자가 “계단 없이 22번 게이트로 가줘”라고 요청하면, VLA 에이전트는 주변의 에스컬레이터나 표지판을 시각적으로 인식하고 혼잡도를 피해 최적의 경로를 AR로 안내합니다. VLA 기반 내비게이션은 “붐비는 곳을 피해서”와 같은 사용자의 추가 요구사항을 실시간으로 반영할 수 있어, 시각 장애인이나 인지 장애인의 접근성을 높이는 데도 크게 기여합니다.
4. Challenges and Limitations of Vision-Language-Action Models
VLA 모델이 연구 프로토타입을 넘어 실제 시스템으로 발전하기 위해서는 다음과 같은 상호 연관된 과제들을 해결해야 합니다.
- 실시간 추론 및 계산 효율성:
- 문제점: 복잡한 시나리오에서 실시간으로 작동하기 위한 계산량 감소가 여전히 어려움 (ex. DeeR-VLA, UniNaVid)
- 영향: 드론, 로봇 팔 등 즉각적인 반응이 필요한 실제 환경에서의 배포를 저해
- 일반화 및 데이터 효율성:
- 문제점: 처음 보는 객체나 환경에 대한 일반화 능력이 아직 부족 (ex. ObjectVLA는 신규 객체의 64%만 일반화). 최소한의 데이터로 안정적인 정책을 학습하는 것이 어려움 (ex. ConRFT는 전문가 개입에 크게 의존)
- 영향: 개방형(open-world) 환경에서의 강건성 및 신뢰성 부족
- 안전성 및 신뢰성 보장:
- 문제점: 동적인 실제 환경에서 안전을 보장하고, 예측 불가능한 상황에 대처하는 것이 힘듦. 다양한 실제 작업에 적용 가능한 포괄적인 안전 규칙 정의가 난제 (ex. SafeVLA)
- 영향: 고위험 환경(의료, 자율주행 등)에서의 상용화에 큰 장벽
- 시스템 통합 및 복잡성:
- 문제점: 다중 모달리티(시각, 언어, 촉각 등)를 통합하고, 계층적 프레임워크(고수준 추론 + 저수준 실행)를 조율하는 것이 복잡함 (ex. Hi Robot, TLA). 모델 병합 전략(ReVLA)은 계산 복잡도를 증가시킴
- 영향: 시스템 개발 및 유지보수의 어려움 증가
- 데이터 편향 및 윤리적 문제:
- 문제점: 훈련 데이터셋의 편향이 모델의 공정성과 의미론적 정확성에 영향을 미침
- 영향: 특정 상황이나 대상에 대해 왜곡되거나 비윤리적인 행동을 할 수 있는 잠재적 위험
이러한 문제들을 해결하기 위해 연구자들은 하드웨어 가속, 하이브리드 정책 모델, 동적 위험 평가 모듈, 편향 제거 데이터셋 등 다양한 기술적 전략을 모색하고 있습니다. 이 과제들을 극복하는 것은 VLA 모델이 실제 로봇 공학의 복잡성 속에서 안정적이고 자율적인 작동을 달성하기 위한 필수적인 과정이며, 본 챕터에서는 이러한 문제들을 심층적으로 분석할 것입니다.
4.1. Real-Time Inference Constraints
실시간 추론 능력은 VLA 모델을 로봇 조작이나 자율 주행과 같이 즉각적인 반응이 필수적인 분야에 배포하는 데 있어 가장 큰 제약 조건 중 하나입니다. 대부분의 VLA 모델이 사용하는 자기회귀 디코딩 방식은 행동 토큰을 하나씩 순차적으로 생성하기 때문에, 추론 속도가 보통 3~5Hz에 그칩니다. 이는 실제 로봇 시스템이 요구하는 100Hz 이상의 제어 주파수에 현저히 미치지 못하여 동적인 환경에서의 활용을 크게 제한합니다.
이 문제를 해결하기 위해 병렬 디코딩과 같은 새로운 기술이 등장하여 여러 토큰을 동시에 예측함으로써 속도를 높이려는 시도가 있었습니다. NVIDIA의 Groot N1 모델이 대표적인 예로, 속도를 약 2.5배 향상시켰지만, 이는 로봇 움직임의 부드러움을 희생하는 대가로 이루어졌습니다. 이러한 갑작스러운 움직임은 특히 수술 로봇과 같이 극도의 정밀성이 요구되는 분야에서는 용납되기 어렵습니다.
또한, 하드웨어의 물리적 한계도 실시간 추론을 어렵게 만드는 주요 원인입니다. VLA 모델이 처리하는 고차원의 시각 정보는 막대한 메모리 대역폭을 필요로 하며, 이는 현재 상용화된 엣지 AI 하드웨어의 성능을 초과합니다. 연산 정밀도를 낮추는 양자화 기술을 사용하면 메모리 부담을 줄일 수 있지만, 이는 모델의 정확도 저하로 이어질 수 있어 근본적인 해결책이 되지 못합니다.
VLA 모델의 실시간 추론 문제는 단순히 속도를 높이는 것뿐만 아니라, ‘속도’와 ‘품질’ 사이의 균형을 맞추는 복합적인 과제입니다. 출력 품질을 저하시키지 않으면서 빠른 추론을 달성하고, 하드웨어 제약을 극복하는 것이 VLA 모델의 실용화를 위한 핵심 연구 방향으로 남아있습니다.
4.2. Multimodal Action Representation and Safety Assurance
VLA 모델이 로봇의 행동을 어떻게 표현하고 생성하는가에 대한 근본적인 2가지 문제가 있습니다.
1. Multimodal Action Representation 첫 번째 중요한 한계점은 지속적이고 미묘한 제어가 필요한 시나리오에서 멀티모달 행동을 정확하게 표현하는 것입니다.
- 이산적(Discrete) 토큰화 방식:
- 개념: 행동을 256개와 같이 정해진 수의 ‘이산값(bin)’으로 나누어 표현
- 한계: 정밀도가 부족하여 섬세한 잡기(grasping)나 외과 수술 같은 미세 작업에서 큰 오류를 유발. 부정확한 움직임으로 이어져 성능과 신뢰성을 저해함
- 연속적(Continuous) MLP 기반 방식:
- 개념: 행동을 연속적인 값으로 표현
- 한계: 여러 가능한 행동 경로가 있음에도 불구하고, 모델이 하나의 경로로만 섣불리 수렴하는 ‘모드 붕괴(mode collapse)’ 현상이 발생. 이는 동적인 환경에서 필요한 적응성과 유연성을 크게 감소시킴.
- 확산(Diffusion) 기반 정책:
- 개념: 다양한 행동 가능성을 포착할 수 있는 풍부한 다중 모달리티 행동 표현을 제공 (ex. \(\pi_0\), RDT-1B)
- 한계: 기존 방식보다 계산 비용이 약 3배 더 높아 실시간 배포가 비현실적임
- 결론: 현재 VLA 모델은 여러 전략이 모두 유효할 수 있는 복잡하고 동적인 작업(ex. 혼잡한 공간 탐색, 양손 조작)에서 효과적인 행동을 생성하는 데 어려움을 겪고 있음.
2. Safety Assurance in Open Worlds 실제 환경의 예측 불가능성 속에서 안전을 보장하는 것은 VLA의 또 다른 중대한 과제입니다.
- 경직된 안전 규칙:
- 문제점: 대부분의 시스템이 사전에 설정된 고정된 힘/토크 임계값에 의존함.
- 한계: 예상치 못한 장애물이나 갑작스러운 환경 변화에 대한 적응성이 매우 떨어짐.
- 부정확한 충돌 예측:
- 문제점: 현재 충돌 예측 모델의 정확도는 혼잡한 공간에서 약 82%에 불과함.
- 한계: 창고 물류나 가정용 로봇처럼 안전 마진이 거의 없는 환경에서 심각한 위험을 초래할 수 있음.
- 비상 정지 메커니즘의 지연:
- 문제점: 필수적인 안전 검증 절차로 인해, 비상 정지와 같은 안전 기능이 작동하는 데 상당한 지연 시간(200~500ms)이 발생
- 한계: 이 짧은 지연 시간조차 자율 주행이나 긴급 구조 로봇과 같이 고속으로 작동하는 환경에서는 치명적인 결과를 낳을 수 있음.
VLA 모델이 실제 세계에서 신뢰를 얻기 위해서는 현재의 기술들은 각각 정밀도 부족, 유연성 상실, 높은 계산 비용, 경직된 대응, 치명적인 지연 시간 등의 한계를 가지고 있어, 이 문제들을 해결하는 것이 VLA의 신뢰성 있는 배포를 위한 핵심 과제입니다.
4.3. Dataset Bias, Grounding, and Generalization to Unseen Tasks
다음은 VLA 모델의 성능을 저해하는 근본적인 문제입니다.
- 데이터셋 편향 (Dataset Bias):
- 원인: 웹에서 대규모로 수집된 훈련 데이터셋은 사회적/문화적 편향을 그대로 담고 있음.
- 사례: 표준 데이터셋의 약 17%가 “의사”는 남성과, “간호사”는 여성과 연결하는 등 성별 고정관념과 같은 편향을 포함함.
- 결과: 편향된 데이터로 학습한 VLA는 실제 환경에서 상황에 맞지 않거나 의미적으로 잘못된 행동을 할 위험이 높음.
- 그라운딩 결함 (Grounding Defects):
- 정의: 언어적 개념을 실제 세계의 시각적 대상이나 상황과 정확하게 연결하지 못하는 문제.
- 사례: OpenVLA 같은 모델은 새로운 환경에서 객체 참조의 약 23%를 놓치는 것으로 나타남. 이는 “저 파란색 컵을 집어줘” 같은 명령을 정확히 수행할 수 없음을 의미.
- 결과: 실제 애플리케이션에서의 유용성과 신뢰도를 심각하게 손상시킴.
- 조합적 일반화(Compositional Generalization) 실패:
- 정의: 학습 데이터에 드물게 나타나는 비전형적인 조합을 이해하지 못하는 문제.
- 사례: “노란색 말”과 같이 흔치 않은 개념 조합을 마주했을 때, 모델이 이를 해석하는 데 실패함.
- 결과: 예측 불가능한 실제 세계의 다양성에 대처하는 능력이 떨어짐.
- 보이지 않는 작업으로의 일반화(broader issue of generalization to unseen tasks) 한계
- 문제점: 모델이 훈련 데이터와 유사한 환경이나 작업에서는 뛰어난 성능을 보이지만, 완전히 새로운 작업이나 환경에 직면하면 성능이 급격히 저하됨 (최대 40%까지 성능 저하).
- 원인:
- 과적합(Overfitting): 좁은 범위의 훈련 데이터 분포에 과도하게 최적화됨.
- 다양성 부족: 다양한 작업 표현에 대한 학습이 불충분함.
- 사례: 가정용 작업에 특화된 VLA 모델을 산업 현장이나 농업 환경에 투입하면, 객체, 환경, 제약 조건이 달라져 제대로 작동하지 못하거나 완전히 실패함.
- 결과: 현재 VLA는 제로샷(Zero-shot) 또는 퓨샷(Few-shot) 학습 능력이 제한적이어서, 실제 환경에서 요구되는 적응성과 확장성이 부족함.
VLA 모델의 실용적인 배포를 위해서는 편향이 제거된 균형 잡힌 데이터셋을 구축하고, 언어와 현실을 정확히 연결하는 고급 그라운딩 기술을 개발하는 것이 필요합니다. 이를 통해 모델이 다양한 환경과 처음 보는 작업에도 유연하게 적응할 수 있는 진정한 일반화 능력을 갖추도록 해야 합니다.
4.4. System Integration Complexity and Computational Demands
VLA 모델을 실제 로봇에 통합하는 과정에서 발생하는 세 가지 주요 문제입니다.
- 이중 시스템 아키텍처의 딜레마: 시간적 불일치 (Temporal Misalignment)
- 개념: VLA는 보통 두 개의 시스템으로 구성됨.
- System 2 (계획 시스템): LLM(GPT, Llama-2 등)을 사용해 고수준의 복잡한 계획을 세움. 매우 느림 (추론에 약 800ms 이상 소요).
- System 1 (제어 시스템): 저수준의 빠른 모터 제어를 실행. 매우 빠름 (약 10ms 간격으로 작동).
- 문제점: 두 시스템의 작동 속도 차이가 너무 커서 동기화가 어렵고, 이로 인해 지연과 불안정한(jerky) 움직임이 발생함 (ex. NVIDIA Groot N1 모델).
- 개념: VLA는 보통 두 개의 시스템으로 구성됨.
- 특징 공간의 불일치 (Feature Space Misalignment)
- 개념: 고차원의 복잡한 시각 정보(Vision Transformer)와 저차원의 단순한 행동 정보(Action Decoder) 간의 데이터 형태가 일치하지 않음.
- 문제점: 이 불일치를 조정하는 과정에서 지각적 이해와 실제 행동 간의 일관성이 깨짐.
- 결과: 특히 시뮬레이션에서 학습한 모델을 실제 로봇에 적용할 때(Sim-to-Real), 센서 노이즈 등으로 인해 성능이 최대 32%까지 저하됨 (ex. OpenVLA, RoboMamba).
- 막대한 계산 및 에너지 요구사항
- 문제점: VLA 모델은 엄청난 수의 파라미터를 가짐 (ex. 7B 이상).
- 요구 사양: 이를 구동하기 위해서는 28GB가 넘는 VRAM 등 막대한 컴퓨팅 자원이 필요.
- 현실의 한계: 이러한 요구 사항은 자율 드론, 모바일 로봇 등 엣지 컴퓨팅(Edge Computing) 환경의 하드웨어 성능을 훨씬 뛰어넘음.
- 결과: 정교하고 성능 좋은 VLA 모델을 자원이 풍부한 연구실 환경 밖의 실제 현장에 배포하는 것을 극도로 어렵게 만듦.
VLA 모델의 실용화를 위해서는, 느린 계획 시스템과 빠른 제어 시스템 간의 속도 차이를 조화시키고, 고차원 인식과 저차원 행동 간의 데이터 불일치를 해소하며, 제한된 하드웨어에서 막대한 계산량을 감당할 수 있는 해결책을 찾는 것이 핵심 과제입니다.
4.5. Robustness and Ethical Challenges in VLA Deployment
VLA 모델을 실제 환경에 배포하는 데에는 ‘환경적 강건성(Robustness)’ 이라는 중대한 과제가 있습니다. 강건성이란 VLA가 조명, 날씨, 소음 등 끊임없이 변하는 실제 환경 속에서도 안정적이고 정확한 성능을 유지하는 능력을 의미하지만, 현재 모델들은 이러한 변화에 매우 취약합니다. 구체적으로, VLA의 시각 모듈은 어둡거나 그림자가 많은 환경에서 정확도가 20~30%까지 떨어지는 문제를 보입니다. 또한, 언어 이해 모듈은 시끄러운 환경에서 음성 명령을 잘못 해석하여 작업 실패를 유발할 수 있습니다. 마지막으로, 로봇의 행동 역시 복잡한 환경, 특히 객체가 부분적으로 가려진 상황에서는 위치나 방향을 잘못 판단하여 임무 수행에 어려움을 겪습니다. 따라서 VLA 모델이 예측 불가능한 실제 세계에서 신뢰를 얻기 위해서는, 시각, 언어, 행동 모든 면에서 다양한 환경 변화에도 흔들리지 않는 강력한 ‘강건성’을 확보하는 것이 필수적인 과제입니다.
5. Discussion
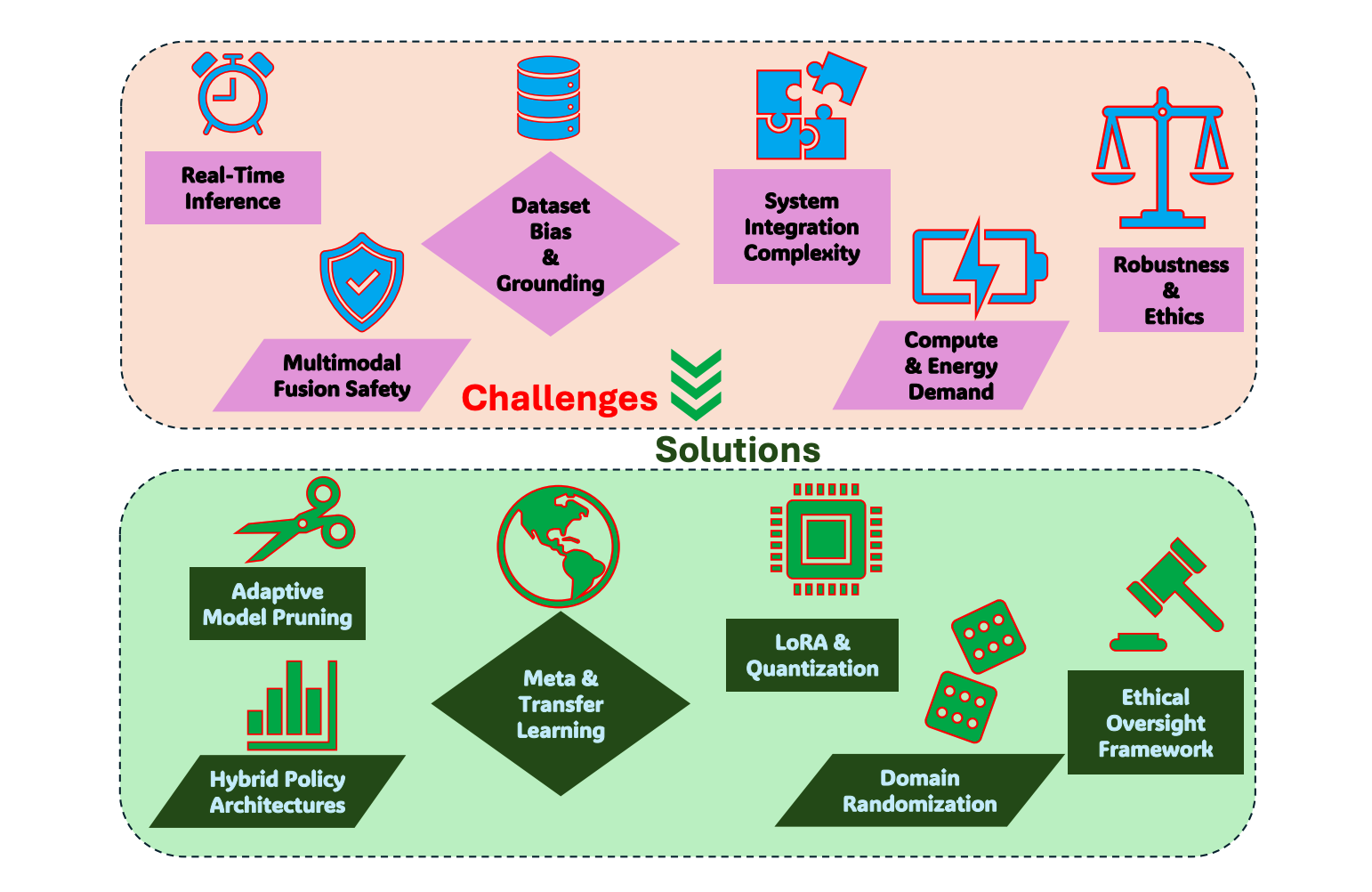
VLA 모델은 실제 환경에 적용되기 위해 알고리즘, 컴퓨팅, 윤리 차원에서 다음과 같은 다면적 과제에 직면해 있습니다.
- 실시간 추론의 어려움: 자기회귀 디코더의 순차적 특성과 고차원 입력 때문에, 제한된 하드웨어에서 실시간 작동이 힘듦.
- 안전 취약성: 비전, 언어, 행동을 하나로 융합하는 과정에서 예측 불가능한 환경 변화에 대한 안전성이 취약해짐.
- 일반화의 한계: 데이터셋 편향과 그라운딩 오류로 인해, 학습 데이터 분포를 벗어난(out-of-distribution) 새로운 작업에 실패하는 경우가 많음.
- 시스템 통합의 복잡성: 인식, 추론, 제어 등 다양한 요소를 통합하면서 아키텍처가 복잡해져 최적화와 유지보수가 어려워짐.
- 막대한 계산 요구사항: 대규모 VLA 모델은 엄청난 에너지와 컴퓨팅 자원을 필요로 하여 모바일/임베디드 플랫폼 배포를 방해함.
- 강건성 및 윤리적 문제: 환경 변화에 대한 강건성 부족과 데이터 편향, 개인정보 보호 등의 윤리적 문제가 사회적/규제적 우려를 낳음.
5.1. Potential Solutions
각 과제에 대한 구체적인 기술적 해결 방안은 다음과 같습니다.
- Real-Time Inference Constraints
- 하드웨어 가속: FPGA, 최적화된 텐서 코어 등 특수 하드웨어를 활용하여 연산 속도를 서브밀리초 단위로 향상
- 모델 압축: LoRA, 지식 증류 등을 통해 파라미터 수를 90%까지 줄여 메모리와 추론 시간 단축
- 점진적 양자화: 혼합 정밀도 연산(FP16/INT8)으로 정확도 손실을 최소화하며 계산량을 2~4배 감소
- 적응형 추론: 입력의 복잡도에 따라 네트워크 깊이를 동적으로 조절하여 불필요한 계산을 건너뜀 (ex. early-exit).
- 효율적 토큰화: 토큰 수를 최소화하는 압축 기법을 사용
- 목표: 일반적인 엣지 GPU에서 50ms 미만의 종단간(end-to-end) 추론 속도를 달성
- Multimodal Action Representation and Safety Assurance.
- 하이브리드 정책: 고수준 계획(자기회귀)과 저수준 행동 샘플링(확산)을 결합하여 유연하고 다양한 행동 생성
- 실시간 위험 평가: 다중 센서 정보를 융합하여 충돌 확률 등을 예측하고, 위험 시 비상 정지 회로를 작동
- 제약 조건 기반 강화학습: 안전 제약 조건을 엄격히 준수하면서 작업 성공률을 극대화하는 정책 학습 (ex. SafeVLA)
- 온라인 모델 적응: 새로운 환경에 실시간으로 적응하여 일관된 안전 성능 보장 (ex. GRPO, DPO)
- 정형 검증(Formal Verification): 신경망 컨트롤러의 출력을 실행 전에 분석하여 안전성을 수학적으로 보장.
- Dataset Bias, Grounding, and Generalization to Unseen Tasks.
- 대규모 편향 없는 데이터셋 구축: 웹 스케일 데이터(LAION-5B)와 로봇 중심 데이터(Open X-Embodiment)를 결합.
- 고급 파인 튜닝: 대조 학습(Contrastive fine-tuning) 등으로 잘못된 상관관계를 줄이고 의미적 정확도 향상.
- 메타 학습 및 지속적 학습: 새로운 작업에 빠르게 적응하고, 과거 지식을 잊지 않도록(catastrophic forgetting 방지) 학습
- 전이 학습: 3D 인식 모델 등을 활용하여 공간적 이해 능력을 부여하고 강건성 향상
- Sim-to-Real 파인 튜닝: 도메인 랜덤화 기법을 사용해 시뮬레이션에서 학습한 정책이 실제 로봇에서 잘 작동하도록 보장
- System Integration Complexity and Computational Demands.
- 모델 모듈화 및 경량화: LoRA 어댑터, 지식 증류, 양자화 인식 훈련 등으로 모델을 가볍고 효율적으로 만듦
- 하드웨어-소프트웨어 공동 설계: VLA 워크로드에 특화된 하드웨어 가속기와 최적화된 툴체인(TensorRT-LLM)을 개발하여 저전력 환경에서 고성능 달성
- 효율적인 아키텍처 개발: 1B 파라미터 미만의 TinyVLA와 같이 작지만 강력한 모델을 설계
- Robustness and Ethical Challenges in VLA Deployment.
- 강건성 향상:
- 도메인 랜덤화: 사실적인 시뮬레이터를 통해 조명, 가려짐 등 다양한 환경 변화에 대한 모델의 저항력을 키움
- 적응형 재보정: 실시간 피드백으로 센서 드리프트 등을 보정
- 윤리적 문제 해결:
- 편향 감사 및 제거: 훈련 데이터를 분석하고, 적대적 편향 제거(adversarial debiasing) 기법으로 수정
- 개인정보 보호: 온디바이스 처리, 동형 암호, 차등 개인정보보호 기술을 적용하여 사용자 데이터 보호
- 사회/경제적 영향 관리: 투명한 영향 평가와 업스킬링 프로그램을 통해 인간 노동을 대체하는 대신 보완하도록 유도
- 규제 및 표준 수립: 책임감 있는 혁신을 위해 안전과 책임에 대한 규제 프레임워크 마련
- 강건성 향상:
5.2. Future Roadmap
VLA 모델의 미래는 단순히 기존 기능을 개선하는 것을 넘어, 범용 로봇 지능의 핵심으로 자리 잡는 방향으로 나아갈 것입니다. 앞으로의 VLA는 웹 스케일의 방대한 데이터로 학습된 거대한 단일 파운데이션 모델을 공유된 ‘대뇌 피질’처럼 사용하여, 물리 법칙과 상식까지 이해하게 될 것입니다.
또한, 로봇은 정적인 학습에서 벗어나, 스스로 목표를 설정하고 시행착오를 통해 배우는 ‘에이전트적 평생 학습’을 수행할 것입니다. 복잡한 명령은 LLM이 상징적 계획으로 분해하고, 신경망 기반 컨트롤러가 이를 유연한 실제 움직임으로 변환하는 ‘계층적 신경-상징 계획’ 방식을 채택할 것입니다. 로봇 내부에 미니 시뮬레이터와 같은 ‘월드 모델’을 탑재하여 예측 불가능한 상황에 실시간으로 적응하고, 로봇의 신체 형태와 무관하게 기술을 공유하는 ‘다양한 신체 간의 전이 학습’이 보편화될 것입니다. 무엇보다, 안전과 윤리, 인간 가치와의 정렬은 선택이 아닌 필수 기능으로 시스템에 내장될 것입니다.
이러한 미래 비전은 ‘VLM-VLA-Agentic AI’ 삼위일체로 구체화될 수 있습니다. 미래의 범용 로봇 “Eva“는 파운데이션 VLM으로 세상을 인지하고, 핵심 VLA 아키텍처로 명령을 계획하고 실행하며, Agentic AI 모듈을 통해 스스로 학습하고 적응합니다. 이 통합된 구조는 로봇이 단순히 명령을 따르는 기계를 넘어, 인지하고, 계획하고, 행동하며, 성장하고, 인간과 안전하게 공존하는 진정한 지능형 파트너로 거듭나게 할 것이며, 이는 체화된 범용 인공지능(Embodied AGI)을 향한 중요한 이정표가 될 것입니다.
6. Conclusion
본 논문은 지난 3년간 폭발적으로 발전해 온 Vision-Language-Action(VLA) 모델의 전반적인 흐름을 체계적으로 조망하는 탁월한 가이드 역할을 한다. 과거 분절되었던 인식, 언어, 행동 시스템이 어떻게 하나의 통합된 프레임워크로 진화했는지, 그리고 이 과정에서 토큰화, 하이브리드 학습, 이중 시스템 아키텍처와 같은 핵심적인 패러다임 전환이 어떻게 이루어졌는지를 명확하게 추적할 수 있었다. 특히 휴머노이드 로봇부터 자율주행, 정밀 농업에 이르기까지 구체적인 응용 사례와 최신 모델들의 기술적 특징을 상세히 분석함으로써, VLA 기술이 단순한 학문적 개념을 넘어 실제 산업 현장에서 어떠한 잠재력을 가지고 있는지 구체적으로 파악하는 데 큰 도움이 되었다.
무엇보다 이 논문의 가장 큰 기여는 VLA 모델이 직면한 5가지 핵심 과제(실시간 추론, 안전성, 일반화, 시스템 통합, 윤리)를 명확히 정의하고, 이에 대한 구체적이고 실현 가능한 기술적 해결 방안을 심도 있게 제시했다는 점이다. 이는 단순히 문제점을 나열하는 데 그치지 않고, 연구자들이 앞으로 나아가야 할 방향을 명확히 제시한다는 점에서 매우 인상 깊었다.
결론적으로, 이 논문을 통해 VLA 모델이 체화된 일반 인공 지능(Embodied AGI)을 향한 여정에서 얼마나 중요한 이정표인지, 그리고 그 목표를 달성하기 위해 우리가 어떤 기술적, 윤리적 허들을 넘어야 하는지를 괄목할 만큼 명확하게 이해할 수 있었다. 앞으로 VLA는 단순히 더 큰 모델을 만드는 것을 넘어, 스스로 학습하고 적응하는 에이전트 AI(Agentic AI)와 융합하여 진정한 지능형 파트너로 거듭날 것이라는 저자의 미래 비전에 깊이 공감하며, 이 분야의 발전에 더욱 큰 기대를 갖게 되었다.